Справочная информация по семейству видеокарт Nvidia GeForce 20
После длительного застоя на рынке графических процессоров, связанного с несколькими факторами, в 2018 году вышло новое поколение GPU компании Nvidia, сразу обеспечившее переворот в 3D-графике реального времени! Аппаратно ускоренной трассировки лучей многие энтузиасты ждали уже давно, так как этот метод рендеринга олицетворяет физически корректный подход к делу, просчитывая путь лучей света, в отличие от растеризации с использованием буфера глубины, к которой мы привыкли за много лет и которая лишь имитирует поведение лучей света. Об особенностях трассировки мы написали большую подробную статью.
Хотя трассировка лучей обеспечивает более высокое качество картинки по сравнению с растеризацией, она весьма требовательна к ресурсам и ее применение ограничено возможностями аппаратного обеспечения. Анонс технологии Nvidia RTX и аппаратно поддерживающих ее GPU дал разработчикам возможность начать внедрение алгоритмов, использующих трассировку лучей, что является самым значительным изменением в графике реального времени за последние годы. Со временем она полностью изменит подход к рендерингу 3D-сцен, но это произойдет постепенно. Поначалу использование трассировки будет гибридным, при сочетании трассировки лучей и растеризации, но затем дело дойдет и до полной трассировки сцены, которая станет доступной через несколько лет.
Что предлагает Nvidia уже сейчас? Компания анонсировала свои игровые решения линейки GeForce RTX в августе 2018 года, на игровой выставке Gamescom. GPU основаны на новой архитектуре Turing, представленной еще чуть ранее — на SIGGraph 2018, когда были рассказаны лишь некоторые подробности о новинках. В линейке GeForce RTX объявлено три модели: RTX 2070, RTX 2080 и RTX 2080 Ti, они основаны на трех графических процессорах: TU106, TU104 и TU102 соответственно. Сразу бросается в глаза, что с появлением аппаратной поддержки ускорения трассировки лучей Nvidia поменяла систему наименований и видеокарт (RTX — от ray tracing, т. е. трассировка лучей), и видеочипов (TU — Turing).

Почему Nvidia решила, что аппаратную трассировку необходимо представить в 2018-м? Ведь прорывов в технологии производства кремния не было, полноценное освоение нового техпроцесса 7 нм еще не закончено, особенно если говорить о массовом производстве таких больших и сложных GPU. И возможностей для заметного повышения количества транзисторов в чипе при сохранении приемлемой площади GPU практически нет. Выбранный для производства графических процессоров линейки GeForce RTX техпроцесс 12 нм FinFET хоть и лучше 16-нанометрового, известного нам по поколению Pascal, но эти техпроцессы весьма близки по своим основным характеристикам, 12-нанометровый использует схожие параметры, обеспечивая чуть большую плотность размещения транзисторов и сниженные утечки тока.
Компания решила воспользоваться своим лидирующим положением на рынке высокопроизводительных графических процессоров, а также фактическим отсутствием конкуренции в момент анонса RTX (лучшие из решений единственного конкурента с трудом дотягивали даже до GeForce GTX 1080) и выпустить новинки с поддержкой аппаратной трассировки лучей именно в этом поколении — еще до возможности массового производства больших чипов по техпроцессу 7 нм.
Кроме модулей трассировки лучей, в составе новых GPU есть аппаратные блоки для ускорения задач глубокого обучения — тензорные ядра, которые достались Turing по наследству от Volta. И надо сказать, что Nvidia идет на приличный риск, выпуская игровые решения с поддержкой двух совершенно новых для пользовательского рынка типов специализированных вычислительных ядер. Главный вопрос заключается в том, смогут ли они получить достаточную поддержку от индустрии — с использованием новых возможностей и новых типов специализированных ядер.
| Графический ускоритель GeForce RTX 2080 Ti | |
|---|---|
| Кодовое имя чипа | TU102 |
| Технология производства | 12 нм FinFET |
| Количество транзисторов | 18,6 млрд (у GP102 — 12 млрд) |
| Площадь ядра | 754 мм² (у GP102 — 471 мм²) |
| Архитектура | унифицированная, с массивом процессоров для потоковой обработки любых видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | DirectX 12, с поддержкой уровня возможностей Feature Level 12_1 |
| Шина памяти | 352-битная: 11 (из 12 физически имеющихся в GPU) независимых 32-битных контроллеров памяти с поддержкой памяти типа GDDR6 |
| Частота графического процессора | 1350 (1545/1635) МГц |
| Вычислительные блоки | 34 потоковых мультипроцессора, включающих 4352 CUDA-ядра для целочисленных расчетов INT32 и вычислений с плавающей запятой FP16/FP32 |
| Тензорные блоки | 544 тензорных ядра для матричных вычислений INT4/INT8/FP16/FP32 |
| Блоки трассировки лучей | 68 RT-ядер для расчета пересечения лучей с треугольниками и ограничивающими объемами BVH |
| Блоки текстурирования | 272 блока текстурной адресации и фильтрации с поддержкой FP16/FP32-компонент и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) | 11 (из 12 физически имеющихся в GPU) широких блоков ROP (88 пикселей) с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра |
| Поддержка мониторов | поддержка подключения по интерфейсам HDMI 2.0b и DisplayPort 1.4a |
| Спецификации референсной видеокарты GeForce RTX 2080 Ti | |
|---|---|
| Частота ядра | 1350 (1545/1635) МГц |
| Количество универсальных процессоров | 4352 |
| Количество текстурных блоков | 272 |
| Количество блоков блендинга | 88 |
| Эффективная частота памяти | 14 ГГц |
| Тип памяти | GDDR6 |
| Шина памяти | 352-бит |
| Объем памяти | 11 ГБ |
| Пропускная способность памяти | 616 ГБ/с |
| Вычислительная производительность (FP16/FP32) | до 28,5/14,2 терафлопс |
| Производительность трассировки лучей | 10 гигалучей/с |
| Теоретическая максимальная скорость закраски | 136-144 гигапикселей/с |
| Теоретическая скорость выборки текстур | 420-445 гигатекселей/с |
| Шина | PCI Express 3.0 |
| Разъемы | один HDMI и три DisplayPort |
| Энергопотребление | до 250/260 Вт |
| Дополнительное питание | два 8-контактных разъема |
| Число слотов, занимаемых в системном корпусе | 2 |
| Рекомендуемая цена | $999/$1199 или 95990 руб. (Founders Edition) |
Как это стало обычным делом для нескольких семейств видеокарт Nvidia, линейка GeForce RTX предлагает специальные модели самой компании — так называемые Founders Edition. В этот раз при более высокой стоимости они обладают и более привлекательными характеристиками. Так, фабричный разгон у таких видеокарт есть изначально, а кроме этого, GeForce RTX 2080 Ti Founders Edition выглядят весьма солидно благодаря удачному дизайну и отличным материалам. Каждая видеокарта протестирована на стабильную работу и обеспечивается трехлетней гарантией.

Видеокарты GeForce RTX Founders Edition имеют кулер с испарительной камерой на всю длину печатной платы и два вентилятора для более эффективного охлаждения. Длинная испарительная камера и большой двухслотовый алюминиевый радиатор обеспечивают большую площадь рассеивания тепла. Вентиляторы отводят горячий воздух в разные стороны, и при этом работают они довольно тихо.
Система питания в GeForce RTX 2080 Ti Founders Edition также серьезно усилена: применяется 13-фазная схема iMon DrMOS (в GTX 1080 Ti Founders Edition была 7-фазная dual-FET), поддерживающая новую динамическую систему управления питанием с более тонким контролем, улучшающая разгонные возможности видеокарты, о которых мы еще поговорим далее. Для питания скоростной GDDR6-памяти установлена отдельная трехфазная схема.
Архитектурные особенности
Применяемая в старшей модели видеокарты GeForce RTX 2080 Ti модификация графического процессора TU102 по количеству блоков ровно вдвое больше, чем TU106, который появился в виде модели GeForce RTX 2070 чуть позднее. Самый же сложный TU102, применяемый в 2080 Ti, имеет площадь 754 мм² и 18,6 млрд транзисторов против 610 мм² и 15,3 млрд транзисторов у топового чипа семейства Pascal — GP100.
Примерно то же самое и с остальными новыми GPU, все они по сложности чипов как бы сдвинуты на шаг: TU102 соответствует TU100, TU104 по сложности похож на TU102, а TU106 — на TU104. Так как GPU усложнились, но техпроцессы применяются очень схожие, то и по площади новые чипы заметно увеличились. Посмотрим, за счет чего графические процессоры архитектуры Turing стали сложнее:
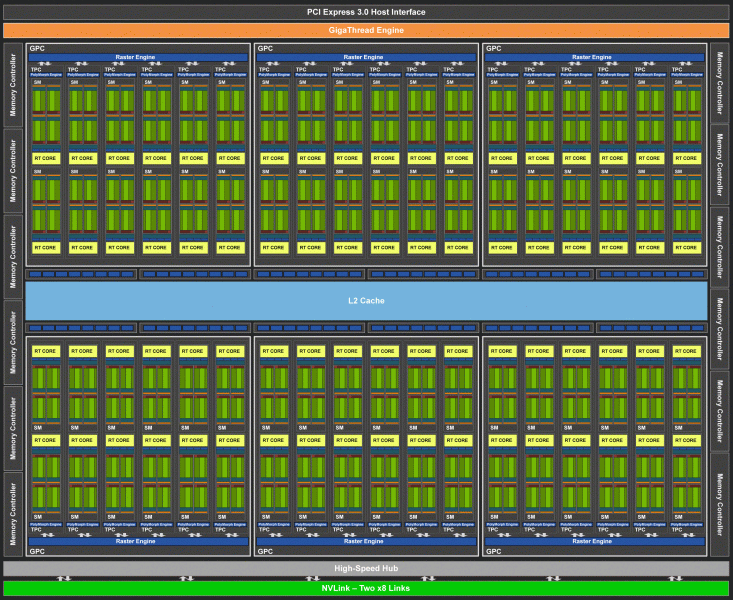
Полный чип TU102 включает шесть кластеров Graphics Processing Cluster (GPC), 36 кластеров Texture Processing Cluster (TPC) и 72 потоковых мультипроцессора Streaming Multiprocessor (SM). Каждый из кластеров GPC имеет собственный движок растеризации и шесть кластеров TPC, каждый из которых, в свою очередь, включает два мультипроцессора SM. Все SM содержат по 64 CUDA-ядра, по 8 тензорных ядер, по 4 текстурных блока, регистровый файл 256 КБ и 96 КБ конфигурируемого L1-кэша и разделяемой памяти. Для нужд аппаратной трассировки лучей каждый мультипроцессор SM имеет также и по одному RT-ядру.
Всего в полной версии TU102 получается 4608 CUDA-ядер, 72 RT-ядра, 576 тензорных ядер и 288 блоков TMU. Графический процессор общается с памятью при помощи 12 отдельных 32-битных контроллеров, что дает 384-битную шину в целом. К каждому контроллеру памяти привязаны по восемь блоков ROP и по 512 КБ кэш-памяти второго уровня. То есть всего в чипе 96 блоков ROP и 6 МБ L2-кэша.
По структуре мультипроцессоров SM новая архитектура Turing очень схожа с Volta, и количество ядер CUDA, блоков TMU и ROP по сравнению с Pascal выросло не слишком сильно — и это при таком усложнении и физическом увеличении чипа! Но это не удивительно, ведь основную сложность привнесли новые типы вычислительных блоков: тензорные ядра и ядра ускорения трассировки лучей.
Еще были усложнены сами CUDA-ядра, в которых появилась возможность одновременного исполнения целочисленных вычислений и операций с плавающей запятой, а также серьезно увеличен объем кэш-памяти. Об этих изменениях мы поговорим далее, а пока что отметим, что при проектировании семейства Turing разработчики намеренно перенесли фокус с производительности универсальных вычислительных блоков в пользу новых специализированных блоков.
Но не следует думать, что возможности CUDA-ядер остались неизменными, их тоже значительно улучшили. По сути, потоковый мультипроцессор Turing основан на варианте Volta, из которого исключена большая часть FP64-блоков (для операций с двойной точностью), но оставлена удвоенная производительность на такт для FP16-операций (также аналогично Volta). Блоков FP64 в TU102 оставлено 144 штуки (по два на SM), они нужны только для обеспечения совместимости. А вот вторая возможность позволит увеличить скорость и в приложениях, поддерживающих вычисления со сниженной точностью, вроде некоторых игр. Разработчики уверяют, что в значительной части игровых пиксельных шейдеров можно смело снизить точность с FP32 до FP16 при сохранении достаточного качества, что также принесет некоторый прирост производительности. Со всеми подробностями работы новых SM можно ознакомиться в обзоре архитектуры Volta.
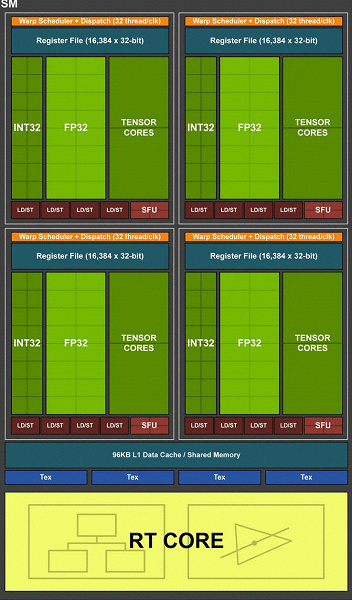
Одним из важнейших изменений потоковых мультипроцессоров является то, что в архитектуре Turing стало возможным одновременное выполнение целочисленных (INT32) команд вместе с операциями с плавающей запятой (FP32). Некоторые пишут, что в CUDA-ядрах «появились» блоки INT32, но это не совсем верно — они «появились» в составе ядер сразу, просто до архитектуры Volta одновременное исполнение целочисленных и FP-инструкций было невозможно, и эти операции запускались на выполнение по очереди. CUDA-ядра архитектуры Turing же схожи с ядрами Volta, которые позволяют исполнять INT32- и FP32-операции параллельно.
И так как игровые шейдеры, помимо операций с плавающей запятой, используют много дополнительных целочисленных операций (для адресации и выборки, специальных функций и т. п.), то это нововведение способно серьезно повысить производительность в играх. По оценкам компании Nvidia, в среднем на каждые 100 операций с плавающей запятой приходится около 36 целочисленных операций. Так что лишь это улучшение способно принести прирост скорости вычислений порядка 36%. Важно отметить, что это касается только эффективной производительности в типичных условиях, а на пиковых возможностях GPU не сказывается. То есть пусть теоретические цифры для Turing и не столь красивы, в реальности новые графические процессоры должны оказаться более эффективными.
Но почему, раз в среднем целочисленных операций лишь 36 на 100 FP-вычислений, количество блоков INT и FP одинаково? Скорее всего, это сделано для упрощения работы управляющей логики, а кроме этого, INT-блоки наверняка значительно проще FP, так что «лишнее» их количество вряд ли сильно повлияло на общую сложность GPU. Ну и задачи графических процессоров Nvidia давно не ограничиваются игровыми шейдерами, а в других применениях доля целочисленных операций вполне может быть и выше. Кстати, аналогично Volta повысился и темп выполнения инструкций для математических операций умножения-сложения с однократным округлением (fused multiply–add — FMA), требующих лишь четырех тактов по сравнению с шестью тактами на Pascal.
В новых мультипроцессорах SM была серьезно изменена и архитектура кэширования, для чего кэш первого уровня и разделяемая память были объединены (у Pascal они были раздельные). Shared-память ранее имела лучшие характеристики по пропускной способности и задержкам, а теперь пропускная способность L1-кэша выросла вдвое, снизились задержки доступа к нему вместе с одновременным увеличением емкости кэша. В новом GPU можно изменять соотношение объема L1-кэша и разделяемой памяти, выбирая из нескольких возможных конфигураций.
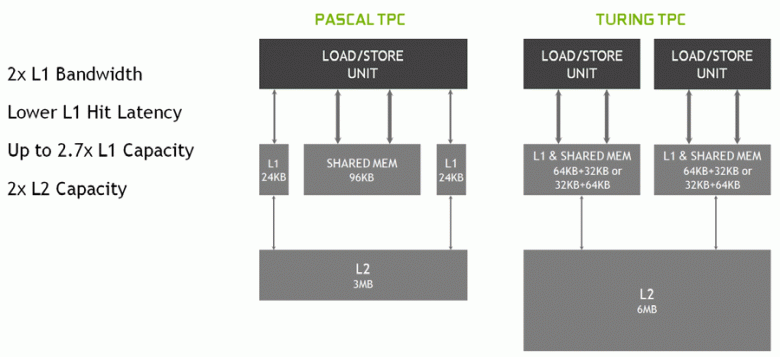
Кроме этого, в каждом разделе мультипроцессора SM появился L0-кэш для инструкций вместо общего буфера, а каждый кластер TPC в чипах архитектуры Turing теперь имеет вдвое больше кэш-памяти второго уровня. То есть общий объем L2-кэша вырос до 6 МБ для TU102 (у TU104 и TU106 его поменьше — 4 МБ).
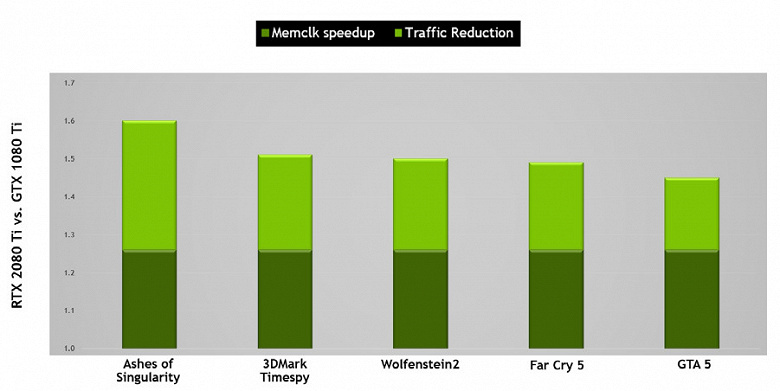
Эти архитектурные изменения привели к 50%-ному улучшению производительности шейдерных процессоров при равной тактовой частоте в таких играх, как Sniper Elite 4, Deus Ex, Rise of the Tomb Raider и других. Но это не значит, что общий рост частоты кадров будет равен 50%, так как общая производительность рендеринга в играх далеко не всегда ограничена именно скоростью вычисления шейдеров.
Также были улучшены технологии сжатия информации без потерь, экономящие видеопамять и ее пропускную способность. Архитектура Turing поддерживает новые техники сжатия — по данным Nvidia, до 50% более эффективные по сравнению с алгоритмами в семействе чипов Pascal. Вместе с применением нового типа памяти GDDR6 это дает приличный прирост эффективной ПСП, так что новые решения не должны быть ограничены возможностями памяти. А при увеличении разрешения рендеринга и повышении сложности шейдеров ПСП играет важнейшую роль в обеспечении общей высокой производительности.
К слову, о памяти. Инженеры Nvidia работали совместно с производителями для обеспечения поддержки нового типа памяти — GDDR6, и все новое семейство GeForce RTX поддерживает микросхемы этого типа, имеющие пропускную способность в 14 Гбит/с и при этом на 20% более энергоэффективные по сравнению с применяемой в топовых Pascal GDDR5X-памятью. Топовый чип TU102 имеет 384-битную шину памяти (12 штук 32-битных контроллеров), но так как один из них отключен в GeForce RTX 2080 Ti, то шина памяти у него 352-битная, и на топовую карту семейства установлено 11, а не 12 ГБ.
Сама по себе GDDR6 хоть и является совершенно новым типом памяти, но слабо отличается от уже использовавшейся ранее GDDR5X. Основное ее отличие — в еще более высокой тактовой частоте при том же напряжении в 1,35 В. А от GDDR5 новый тип отличается тем, что имеет два независимых 16-битных канала с собственными шинами команд и данных — в отличие от единого 32-битного интерфейса GDDR5 и не полностью независимых каналов в GDDR5X. Это позволяет оптимизировать передачу данных, а более узкая 16-битная шина работает эффективнее.
Характеристики GDDR6 обеспечивают высокую пропускную способность памяти, которая стала значительно выше, чем была у предыдущего поколения GPU, поддерживающего типы памяти GDDR5 и GDDR5X. Рассматриваемая сегодня GeForce RTX 2080 Ti имеет ПСП на уровне 616 ГБ/с, что выше и чем у предшественников, и чем у конкурирующей видеокарты, использующей дорогую память стандарта HBM2. В будущем характеристики памяти GDDR6 будут улучшаться, сейчас ее выпускают компании Micron (скорость от 10 до 14 Гбит/с) и Samsung (14 и 16 Гбит/с).
Другие нововведения
Добавим немного информации о других нововведениях Turing, которые будут полезны и для старых, и для новых игр. К примеру, по некоторым фичам (feature level) из Direct3D 12 чипы Pascal отставали от решений AMD и даже Intel! В частности, это касается таких возможностей, как Constant Buffer Views, Unordered Access Views и Resource Heap (возможности, облегчающие работу программистов, упрощая доступ к различным ресурсам). Так вот, по этим возможностям Direct3D feature level новые GPU компании Nvidia теперь практически не отстают от конкурентов, поддерживая уровень Tier 3 для Constant Buffer Views и Unordered Access Views и Tier 2 для resource heap.
Единственная возможность D3D12, которая есть у конкурентов, но не поддерживается в Turing — PSSpecifiedStencilRefSupported: возможность вывести из пиксельного шейдера референсное значение стенсиля, иначе его можно установить только глобально для всего вызова функции отрисовки. В некоторых старых играх стенсиль использовался для отсечения источников освещения в различных регионах экрана, и эта возможность была полезна для занесения в стенсиль маски с несколькими разными значениями, чтобы каждому источнику света отрисовываться в своем проходе со стенсил-тестом. Без PSSpecifiedStencilRefSupported эту маску приходится рисовать в несколько проходов, а так можно сделать один, вычисляя значение стенсиля непосредственно в пиксельном шейдере. Вроде бы штука полезная, но в реальности не сильно важна — проходы эти несложные, и заполнение стенсиля в несколько проходов мало на что влияет при современных GPU.
Зато с остальным все в порядке. Появилась поддержка удвоенного темпа исполнения инструкций с плавающей запятой, и в том числе в Shader Model 6.2 — новой шейдерной модели DirectX 12, которая включает нативную поддержку FP16, когда вычисления производятся именно в 16-битной точности и драйвер не имеет права использовать FP32. Предыдущие GPU игнорировали установку min precision FP16, используя FP32, когда им вздумается, а в SM 6.2 шейдер может потребовать использование именно 16-битного формата.
Кроме этого, было серьезно улучшено еще одно больное место чипов Nvidia — асинхронное исполнение шейдеров, высокой эффективностью которого отличаются решения AMD. Async compute уже неплохо работал в последних чипах семейства Pascal, но в Turing эта возможность была еще улучшена. Асинхронные вычисления в новых GPU полностью переработаны, и на одном и том же шейдерном мультипроцессоре SM могут запускать и графические, и вычислительные шейдеры, как и чипы AMD.
Но и это еще не все, чем может похвастать Turing. Многие изменения в этой архитектуре нацелены на будущее. Так, Nvidia предлагает метод, позволяющий значительно снизить зависимость от мощности CPU и одновременно с этим во много раз увеличить количество объектов в сцене. Бич API/CPU overhead давно преследует ПК-игры, и хотя он частично решался в DirectX 11 (в меньшей степени) и DirectX 12 (в несколько большей, но все равно не полностью), радикально ничего не изменилось — каждый объект сцены требует нескольких вызовов функций отрисовки (draw calls), каждый из которых требует обработки на CPU, что не дает GPU показать все свои возможности.
Слишком многое сейчас зависит от производительности центрального процессора, и даже современные многопоточные модели не всегда справляются. Кроме этого, если минимизировать «вмешательство» CPU в процесс рендеринга, то можно открыть множество новых возможностей. Конкурент Nvidia при анонсе своего семейства Vega предложил возможное решение проблем — primivtive shaders, но дело не пошло дальше заявлений. Turing предлагает аналогичное решение под названием mesh shaders — это целая новая шейдерная модель, которая ответственна сразу за всю работу над геометрией, вершинами, тесселяцией и т. д.

Mesh shading заменяет вершинные и геометрические шейдеры и тесселяцию, а весь привычный вершинный конвейер заменяется аналогом вычислительных шейдеров для геометрии, которыми можно делать все, что нужно разработчику: трансформировать вершины, создавать их или убирать, используя вершинные буферы в своих целях как угодно, создавая геометрию прямо на GPU и отправляя ее на растеризацию. Естественно, такое решение может сильно снизить зависимость от мощности CPU при рендеринге сложных сцен и позволит создавать богатые виртуальные миры с огромным количеством уникальных объектов. Такой метод также позволит использовать более эффективное отбрасывание невидимой геометрии, продвинутые техники уровня детализации (LOD — level of detail) и даже процедурную генерацию геометрии.

Но столь радикальный подход требует поддержки от API — наверное, поэтому у конкурента дело дальше заявлений не пошло. Вероятно, в Microsoft работают над добавлением этой возможности, раз она востребована уже двумя основными производителями GPU, и в какой-то из будущих версий DirectX она появится. Ну а пока что ее можно использовать в OpenGL и Vulkan через расширения, а в DirectX 12 — при помощи специализированного NVAPI, который как раз и создан для внедрения возможностей новых GPU, еще не поддерживаемых в общепринятых API. Но так как это не универсальный для всех производителей GPU метод, то широкой поддержки mesh shaders в играх до обновления популярных графических API, скорее всего, не будет.
Еще одна интереснейшая возможность Turing называется Variable Rate Shading (VRS) — это шейдинг с переменным количеством сэмплов. Эта новая возможность дает разработчику контроль над тем, сколько выборок использовать в случае каждого из тайлов буфера размером 4×4 пикселя. То есть для каждого тайла изображения из 16 пикселей можно выбрать свое качество на этапе закраски пикселя — как меньшее, так и большее. Важно, что это не касается геометрии, так как буфер глубины и все остальное остается в полном разрешении.
Зачем это нужно? В кадре всегда есть участки, на которых легко можно понизить количество сэмплов закраски практически без потерь в качестве — к примеру, это части изображения, замыленные постэффектами типа Motion Blur или Depth of Field. А на каких-то участках можно, наоборот, увеличить качество закраски. И разработчик сможет задавать достаточное, по его мнению, качество шейдинга для разных участков кадра, что увеличит производительность и гибкость. Сейчас для подобных задач применяют так называемый checkerboard rendering, но он не универсален и ухудшает качество закраски для всего кадра, а с VRS можно делать это максимально тонко и точно.

Можно упрощать шейдинг тайлов в несколько раз, чуть ли не одну выборку для блока в 4×4 пикселя (такая возможность не показана на картинке, но она есть), а буфер глубины остается в полном разрешении, и даже при таком низком качестве шейдинга границы полигонов будут сохраняться в полном качестве, а не один на 16. К примеру, на картинке выше самые смазанные участки дороги рендерятся с экономией ресурсов вчетверо, остальные — вдвое, и лишь самые важные отрисовываются с максимальным качеством закраски. Так и в других случаях можно отрисовывать с меньшим качеством низкодетализированные поверхности и быстро движущиеся объекты, а в приложениях виртуальной реальности снижать качество закраски на периферии.
Кроме оптимизации производительности, эта технология дает и некоторые неочевидные сходу возможности, вроде почти бесплатного сглаживания геометрии. Для этого нужно отрисовывать кадр в вчетверо большем разрешении (как бы суперсэмплинг 2×2), но включить shading rate на 2×2 по всей сцене, что убирает стоимость вчетверо большей работы по закраске, но оставляет сглаживание геометрии в полном разрешении. Таким образом получается, что шейдеры исполняются лишь один раз на пиксель, но сглаживание получается как 4х MSAA практически бесплатно, поскольку основная работа GPU заключается именно в шейдинге. И это лишь один из вариантов использования VRS, наверняка программисты придумают и другие.
Нельзя не отметить и появление высокопроизводительного интерфейса NVLink второй версии, который уже используется в ускорителях высокопроизводительных вычислений Tesla. Топовый чип TU102 имеет два порта NVLink второго поколения, имеющие общую пропускную способность в 100 ГБ/с (к слову, в TU104 один такой порт, а TU106 лишен поддержки NVLink вовсе). Новый интерфейс заменяет разъемы SLI, а пропускной способности даже одного порта хватит для передачи кадрового буфера с разрешением 8К в режиме многочипового рендеринга AFR от одного GPU к другому, а передача буфера 4K-разрешения доступна на скоростях до 144 Гц. Два порта расширяют возможности SLI сразу до нескольких мониторов с разрешением 8K.
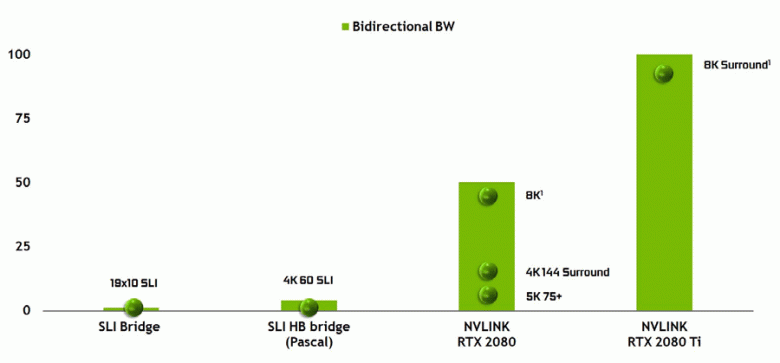
Такая высокая скорость передачи данных позволяет использовать локальную видеопамять соседнего GPU (присоединенного по NVLink, разумеется) практически как свою собственную, и это делается автоматически, без необходимости сложного программирования. Это будет весьма полезно в неграфических применениях и уже применяется в профессиональных приложениях с поддержкой аппаратной трассировки лучей (две видеокарты Quadro c 48 ГБ памяти каждая способны работать над сценой практически как единый GPU с 96 ГБ памяти, для чего ранее приходилось делать копии сцены в памяти обоих GPU), но в будущем это станет полезно и при более сложном взаимодействии многочиповых конфигураций в рамках возможностей DirectX 12. В отличие от SLI, быстрый обмен информацией по NVLink позволит организовать иные формы работы над кадром, чем AFR со всеми его недостатками.
Аппаратная поддержка трассировки лучей
Как стало известно из анонса архитектуры Turing и профессиональных решений линейки Quadro RTX на конференции SIGGraph, новые графические процессоры компании Nvidia, кроме ранее известных блоков, впервые включают также и специализированные RT-ядра, предназначенные для аппаратного ускорения трассировки лучей. Пожалуй, большая часть дополнительных транзисторов в новых GPU принадлежит именно к этим блокам аппаратной трассировки лучей, ведь количество традиционных исполнительных блоков выросло не слишком сильно, хотя и тензорные ядра немало повлияли на увеличение сложности GPU.
Nvidia сделала ставку на аппаратное ускорение трассировки при помощи специализированных блоков, и это большой шаг вперед для качественной графики в реальном времени. Мы уже публиковали большую подробную статью о трассировке лучей в реальном времени, гибридном подходе и его преимуществах, которые проявятся уже в ближайшее время. Настоятельно советуем ознакомиться, в этом материале мы расскажем о трассировке лучей лишь очень кратко.
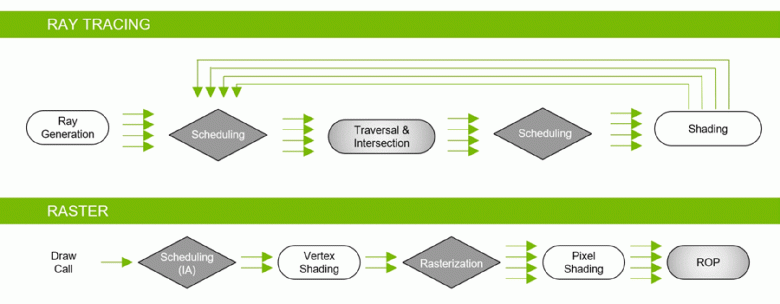
Благодаря семейству GeForce RTX уже сейчас можно использовать трассировку для некоторых эффектов: качественных мягких теней (реализовано в игре Shadow of the Tomb Raider), глобального освещения (ожидается в Metro Exodus и Enlisted), реалистичных отражений (будет в Battlefield V), а также сразу нескольких эффектов одновременно (показано на примерах Assetto Corsa Competizione, Atomic Heart и Control). При этом для GPU, не имеющих аппаратных RT-ядер в своем составе, можно использовать или привычные методы растеризации, или трассировку на вычислительных шейдерах, если это будет не слишком медленно. Вот так по-разному обрабатывают трассировку лучей архитектуры Pascal и Turing:
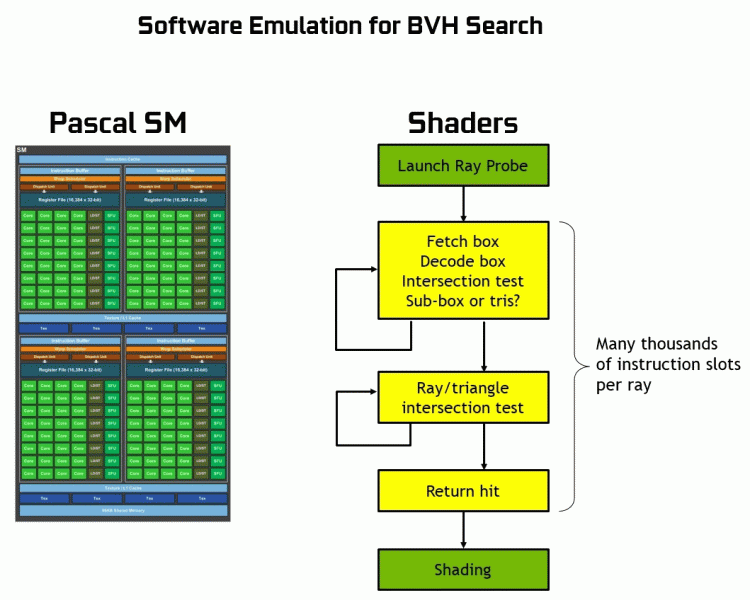
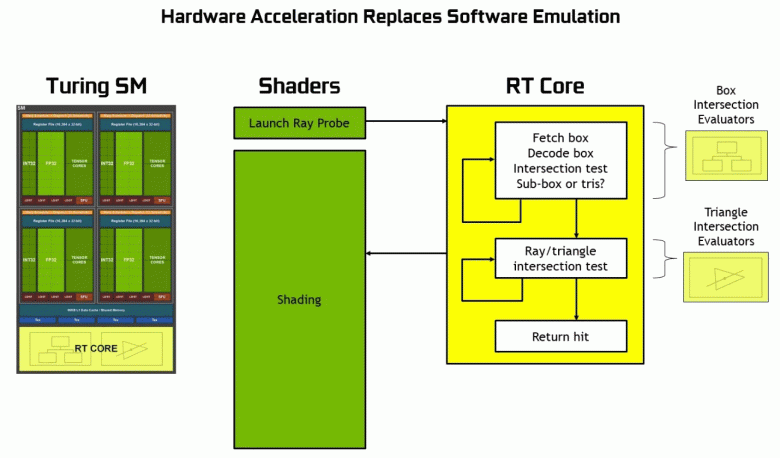
Как видите, RT-ядро полностью принимает на себя работу по определению пересечений лучей с треугольниками. Скорее всего, графические решения без RT-ядер в своем составе будут смотреться не слишком сильно в проектах с применением трассировки лучей, ведь эти ядра специализируются исключительно на расчетах пересечения луча с треугольниками и ограничивающими объемами (BVH), оптимизирующими процесс и важнейшими для ускорения процесса трассировки.
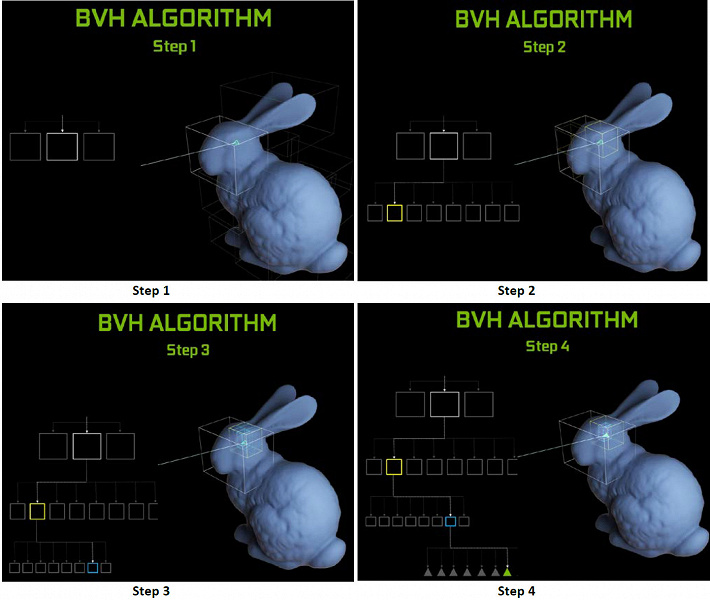
Каждый мультипроцессор в чипах Turing содержит RT-ядро, выполняющее поиск пересечений между лучами и полигонами, а чтобы не перебирать все геометрические примитивы, в Turing используется распространенный алгоритм оптимизации — иерархия ограничивающих объемов (Bounding Volume Hierarchy — BVH). Каждый полигон сцены принадлежит к одному из объемов (коробок), помогающих наиболее быстро определить точку пересечения луча с геометрическим примитивом. При работе BVH нужно рекурсивно обойти древовидную структуру таких объемов. Сложности могут возникнуть разве что для динамически изменяемой геометрии, когда придется менять и структуру BVH.
Что касается производительности новых GPU при трассировке лучей, то публике назвали цифру в 10 гигалучей в секунду для топового решения GeForce RTX 2080 Ti. Не очень понятно, много это или мало, да и оценивать производительность в количестве обсчитываемых лучей в секунду непросто, так как скорость трассировки очень сильно зависит от сложности сцены и когерентности лучей и может отличаться в десяток раз и более. В частности, слабо когерентные лучи при обсчете отражений и преломлений требуют большего времени для расчета по сравнению с когерентными основными лучами. Так что показатели эти чисто теоретические, а сравнивать разные решения нужно в реальных сценах при одинаковых условиях.
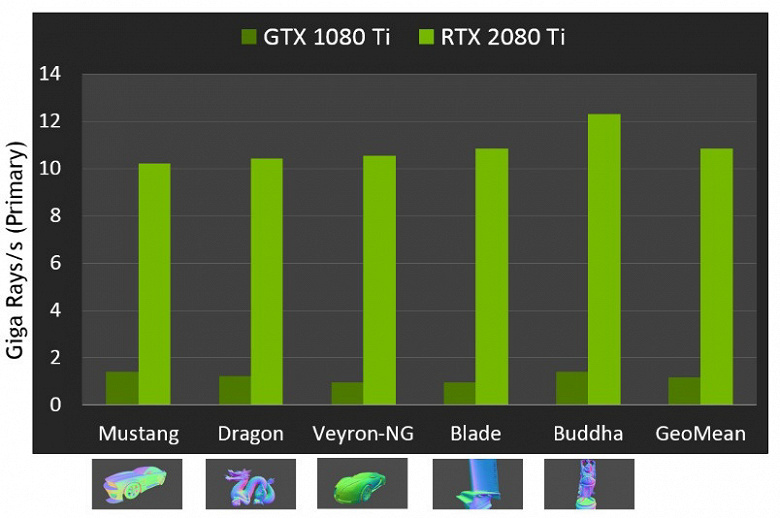
Но Nvidia сравнила новые GPU с предыдущим поколением, и в теории они оказались до 10 раз быстрее в задачах трассировки. В реальности же разница между RTX 2080 Ti и GTX 1080 Ti будет, скорее, ближе к 4-6-кратной. Но даже это — просто отличный результат, недостижимый без применения специализированных RT-ядер и ускоряющих структур типа BVH. Так как бо́льшая часть работы при трассировке выполняется на выделенных RT-ядрах, а не CUDA-ядрах, то снижение производительности при гибридном рендеринге будет заметно ниже, чем у Pascal.
Мы уже показывали вам первые демонстрационные программы с применением трассировки лучей. Некоторые из них были более зрелищными и качественными, другие впечатляли меньше. Но о потенциальных возможностях трассировки лучей не стоит судить по первым выпущенным демонстрациям, в которых намеренно выпячивают на первый план именно эти эффекты. Картинка с трассировкой лучей всегда реалистичнее в целом, но на данном этапе массы еще готовы мириться с артефактами при расчете отражений и глобального затенения в экранном пространстве, а также другими хаками растеризации.


Игровым разработчикам очень нравится трассировка, их аппетиты растут на глазах. Создатели игры Metro Exodus сначала планировали добавить в игру лишь расчет Ambient Occlusion, добавляющий теней в основном в углах между геометрией, но затем они решили внедрить уже полноценный расчет глобального освещения GI, который выглядит впечатляюще.
Кто-то скажет, что ровно так же можно предварительно рассчитать GI и/или тени и «запечь» информацию об освещении и тенях в специальные лайтмапы, но для больших локаций с динамическим изменением погодных условий и времени суток сделать это просто невозможно! Хотя растеризация при помощи многочисленных хитрых хаков и трюков действительно добилась отличных результатов, когда во многих случаях картинка выглядит достаточно реалистично для большинства людей, все же в некоторых случаях отрисовать корректные отражения и тени при растеризации невозможно физически.
Самый явный пример — отражения объектов, которые находятся вне сцены — типичными методами отрисовки отражений без трассировки лучей отрисовать их невозможно в принципе. Также не получится сделать реалистичные мягкие тени и корректно рассчитать освещение от больших по размеру источников света (площадные источники света — area lights). Для этого пользуются разными хитростями, вроде расстановки вручную большого количества точечных источников света и фейкового размытия границ теней, но это не универсальный подход, он работает только в определенных условиях и требует дополнительной работы и внимания от разработчиков. Для качественного же скачка в возможностях и улучшении качества картинки переход к гибридному рендерингу и трассировке лучей просто необходим.
Трассировку лучей можно применять дозированно, для отрисовки определенных эффектов, которые сложно сделать растеризацией. Точно такой же путь в свое время проходила киноиндустрия, в которой в конце прошлого века применялся гибридный рендеринг с одновременной растеризацией и трассировкой. А еще через 10 лет все в кино постепенно перешли к полноценной трассировке лучей. То же самое будет и в играх, этот шаг с относительно медленной трассировкой и гибридным рендерингом невозможно пропустить, так как он дает возможность подготовиться к трассировке всего и вся.
Тем более, что во многих хаках растеризации уже и так используются схожие с трассировкой методы (к примеру, можно взять самые продвинутые методы имитации глобального затенения и освещения), поэтому более активное использование трассировки в играх — лишь дело времени. Заодно она позволяет упростить работу художников по подготовке контента, избавляя от необходимости расставлять фейковые источники света для имитации глобального освещения и от некорректных отражений, которые с трассировкой будут выглядеть естественно.
Переход к полной трассировке лучей (path tracing) в киноиндустрии привел к увеличению времени работы художников непосредственно над контентом (моделированием, текстурированием, анимацией), а не над тем, как сделать неидеальные методы растеризации реалистичными. К примеру, сейчас очень много времени уходит на рассатнвоку источников света, предварительный расчет освещения и «запекание» его в статические карты освещения. При полноценной трассировке это будет не нужно вовсе, и даже сейчас подготовка карт освещения на GPU вместо CPU даст ускорение этого процесса. То есть переход на трассировку обеспечит не только улучшение картинки, но и скачок в качестве самого контента.
В большинстве игр возможности GeForce RTX будут использоваться через DirectX Raytracing (DXR) — универсальный API Microsoft. Но для GPU без аппаратной/программной поддержки трассировки лучей также можно использовать D3D12 Raytracing Fallback Layer — библиотеку, которая эмулирует DXR при помощи вычислительных шейдеров. Эта библиотека имеет схожий, хоть и отличающийся интерфейс по сравнению с DXR, и это несколько разные вещи. DXR — это API, реализуемый непосредственно в драйвере GPU, он может быть реализован как аппаратно, так и полностью программно, на тех же вычислительных шейдерах. Но это будет разный код с разной производительностью. Вообще, изначально Nvidia не планировала поддерживать DXR на своих решениях до архитектуры Volta, но теперь и видеокарты семейства Pascal работают через DXR API, а не только через D3D12 Raytracing Fallback Layer.
Тензорные ядра для интеллекта
Потребности в производительности для работы нейросетей все большего размера и сложности постоянно растут, и в архитектуре Volta добавили новый тип специализированных вычислительных ядер — тензорные ядра. Они помогают получить многократный рост производительности по обучению и инференсу больших нейронных сетей, используемых в задачах искусственного интеллекта. Операции матричного перемножения лежат в основе обучения и инференса (выводы на основе уже обученной нейросети) нейронных сетей, они используются для умножения больших матриц входных данных и весов в связанных слоях сети.
Тензорные ядра специализируются на выполнении конкретно таких перемножений, они значительно проще универсальных ядер и способны серьезно увеличить производительность таких вычислений при сохранении сравнительно небольшой сложности в транзисторах и площади. Мы подробно писали обо всем этом в обзоре вычислительной архитектуры Volta. Кроме перемножения матриц FP16, тензорные ядра в Turing умеют оперировать и с целыми числами в форматах INT8 и INT4 — с еще большей производительностью. Такая точность подходит для применения в некоторых нейросетях, не требующих высокой точности представления данных, зато скорость расчетов возрастает еще вдвое и вчетверо. Пока что экспериментов с использованием пониженной точности не очень много, но потенциал ускорения в 2-4 раза может открыть новые возможности.
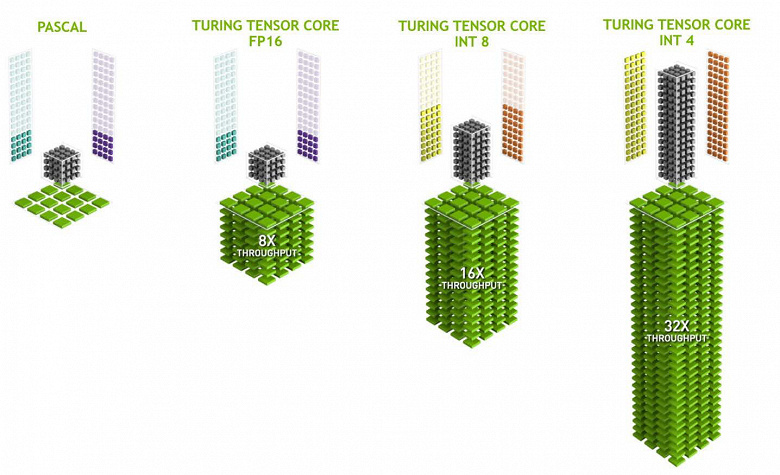
Важно, что эти операции можно выполнять параллельно с CUDA-ядрами, только FP16-операции в последних использует то же самое «железо», что и тензорные ядра, поэтому FP16 нельзя исполнять параллельно на CUDA-ядрах и на тензорных. Тензорные ядра могут исполнять или тензорные инструкции, или FP16-инструкции, и в этом случае их возможности используются не полностью. Скажем, сниженная точность FP16 дает прирост в темпе вдвое по сравнению с FP32, а использование тензорной математики — в 8 раз. Но тензорные ядра — специализированные, они не очень хорошо подходят для произвольных вычислений: умеют выполнять только матричное перемножение в фиксированной форме, которое используется в нейронных сетях, но не в обычных графических применениях. Впрочем, вполне возможно, что игровые разработчики придумают и другие применения тензорам, не связанные с нейросетями.
Но и задачи с применением искусственного интеллекта (глубокое обучение) уже сейчас применяют широко, в том числе они появятся и в играх. Главное, для чего потенциально нужны тензорные ядра в GeForce RTX — для помощи все той же трассировке лучей. На начальной стадии применения аппаратной трассировки производительности хватает только для сравнительно малого количества рассчитываемых лучей на каждый пиксель, а малое количество рассчитываемых сэмплов дает весьма «шумную» картинку, которую приходится обрабатывать дополнительно (подробности читайте в нашей статье о трассировке).
В первых игровых проектах обычно применяется расчет от 1 до 3-4 лучей на пиксель, в зависимости от задачи и алгоритма. К примеру, в ожидаемой в следующем году игре Metro Exodus для расчета глобального освещения с применением трассировки используется по три луча на пиксель с расчетом одного отражения, и без дополнительной фильтрации и шумопонижения результат к применению не слишком пригоден.

Для решения этой проблемы можно использовать различные фильтры шумопонижения, улучшающие результат без необходимости увеличения количества выборок (лучей). Шумодавы очень эффективно устраняют неидеальность результата трассировки со сравнительно малым количеством выборок, и результат их работы зачастую почти не отличить от изображения, полученного с помощью в разы большего количества выборок. На данный момент в Nvidia используют различные шумодавы, в том числе основанные на работе нейросетей, которые как раз и могут быть ускорены на тензорных ядрах.
В будущем такие методы с применением ИИ будут улучшаться, они способны полностью заменить все остальные. Главное, что нужно понять: на текущем этапе применениям трассировки лучей без фильтров шумоподавления не обойтись, именно поэтому тензорные ядра обязательно нужны в помощь RT-ядрам. В играх нынешние реализации пока что не используют тензорные ядра, у Nvidia хоть и есть реализация шумоподавления при трассировке, которая использует тензорные ядра — в OptiX, но из-за скорости работы алгоритма его пока что не получается применить в играх. Но его наверняка можно упростить, чтобы использовать в том числе и в игровых проектах.
Однако использовать искусственный интеллект (ИИ) и тензорные ядра можно не только для этой задачи. Nvidia уже показывала новый метод полноэкранного сглаживания — DLSS (Deep Learning Super Sampling). Его правильнее назвать улучшителем качества картинки, потому что это не привычное сглаживание, а технология, использующая искусственный интеллект для улучшения качества отрисовки аналогично сглаживанию. Для работы DLSS нейросеть сначала «тренируют» в офлайне на тысячах изображений, полученных с применением суперсэмплинга с количеством выборок 64 штуки, а затем уже в реальном времени на тензорных ядрах исполняются вычисления (инференс), которые «дорисовывают» изображение.

То есть нейросеть на примере тысяч хорошо сглаженных изображений из конкретной игры учат «додумывать» пиксели, делая из грубой картинки сглаженную, и она затем успешно делает это уже для любого изображения из той же игры. Такой метод работает значительно быстрее любого традиционного, да еще и с лучшим качеством — в частности, вдвое быстрее, чем GPU предыдущего поколения с использованием традиционных методов сглаживания типа TAA. У DLSS пока что есть два режима: обычный DLSS и DLSS 2x. Во втором случае рендеринг осуществляется в полном разрешении, а в упрощенном DLSS используется сниженное разрешение рендеринга, но обученная нейросеть дорисовывает кадр до полного разрешения экрана. В обоих случаях DLSS дает более высокое качество и стабильность по сравнению с TAA.
К сожалению, у DLSS есть один немаловажный недостаток: для внедрения этой технологии нужна поддержка со стороны разработчиков, так как для работы метода требуются данные из буфера с векторами движения. Но таких проектов уже довольно много, на сегодняшний день есть 25 поддерживающих эту технологию игр, включая такие известные, как Final Fantasy XV, Hitman 2, PlayerUnknown’s Battlegrounds, Shadow of the Tomb Raider, Hellblade: Senua’s Sacrifice и другие.

Но и DLSS — это еще не все, для чего можно применять нейросети. Все зависит от разработчика, он может использовать мощь тензорных ядер для более «умного» игрового ИИ, улучшенной анимации (такие методы уже есть), да много чего еще можно придумать. Главное, что возможности применения нейросетей фактически безграничны, мы просто еще даже не догадываемся о том, что́ можно сделать с их помощью. Раньше производительности было слишком мало для того, чтобы применять нейросети массово и активно, а теперь, с появлением тензорных ядер в простых игровых видеокартах (пусть пока только дорогих) и возможностью их использования при помощи специального API и фреймворка Nvidia NGX (Neural Graphics Framework), это становится всего лишь делом времени.
Автоматизация разгона
Видеокарты Nvidia давно используют динамическое повышение тактовой частоты в зависимости от загрузки GPU, питания и температуры. Этот динамический разгон контролируется алгоритмом GPU Boost, постоянно отслеживающим данные от встроенных сенсоров и меняющим характеристики GPU по частоте и напряжению питания в попытках выжать максимум возможной производительности из каждого приложения. Четвертое поколение GPU Boost добавляет возможность ручного управления алгоритмом работы разгона GPU Boost.
Алгоритм работы в GPU Boost 3.0 был полностью зашит в драйвере, и пользователь никак не мог повлиять на него. А в GPU Boost 4.0 ввели возможность ручного изменения кривых для увеличения производительности. К линии температур можно добавить несколько точек, и вместо прямой теперь используется ступенчатая линия, а частота не сбрасывается до базовой сразу же, обеспечивая бо́льшую производительность при определенных температурах. Пользователь может изменить кривую самостоятельно для достижения более высокой производительности.
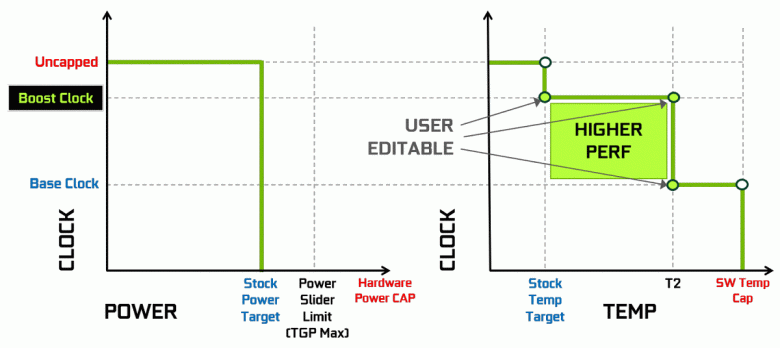
Кроме этого, впервые появилась такая новая возможность, как автоматизированный разгон. Это энтузиасты умеют разгонять видеокарты, но к ним относятся далеко не все пользователи, и не все могут или хотят заниматься ручным подбором характеристик GPU для повышения производительности. В Nvidia решили облегчить задачу для обычных пользователей, позволив каждому разогнать свои GPU буквально нажатием одной кнопки — при помощи Nvidia Scanner.
Nvidia Scanner запускает отдельный поток для тестирования возможностей GPU, который использует математический алгоритм, автоматически определяющий ошибки в расчетах и стабильность работы видеочипа на разных частотах. То есть то, что обычно делается энтузиастом на протяжении нескольких часов, с зависаниями, перезагрузками и прочими фокусами, теперь может сделать автоматизированный алгоритм, требующий на перебор всех возможностей не более 20 минут. Для прогрева и тестирования GPU при этом используются встроенные в чип специальные тесты. Технология закрытая, поддерживается пока только семейством GeForce RTX, и на Pascal она вряд ли заработает.
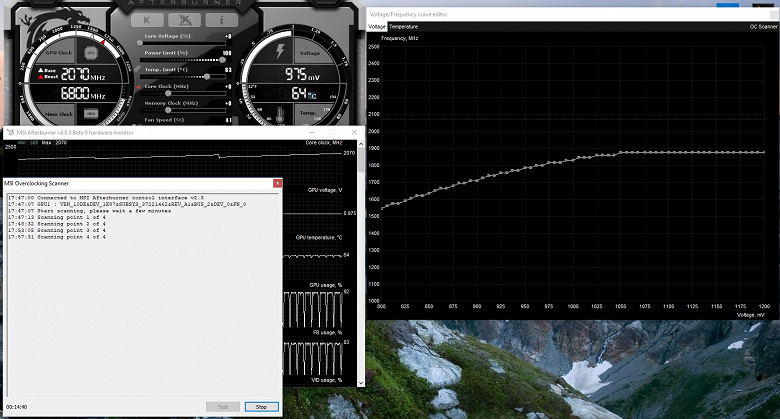
Эта возможность уже внедрена в такой известный инструмент как MSI AfterBurner. Пользователю этой утилиты доступно два основных режима: «Тест», в котором проверяется стабильность разгона GPU, и «Сканирование», когда алгоритмы Nvidia подбирают максимальные настройки разгона автоматически.
В режиме тестирования выдается результат стабильности работы в процентах (100% — полностью стабильно), а в режиме сканирования результат выводится в виде уровня разгона ядра в МГц, а также в виде измененной кривой частот/напряжения. Тестирование в MSI AfterBurner занимает около 5 минут, сканирование — 15-20 минут. В окне редактора кривой частот/напряжений можно увидеть текущие частоту и напряжение GPU, контролируя разгон. В режиме сканирования тестируется не вся кривая, а лишь несколько точек в выбранном диапазоне напряжений, в которых работает чип. Затем алгоритм находит максимально стабильный разгон для каждой из точек, повышая частоту при фиксированном напряжении. По завершении процесса OC Scanner пересылает в MSI Afterburner модифицированную кривую частот/напряжений.
Конечно, это далеко не панацея, и опытный любитель разгона выжмет из GPU еще больше. Да и автоматические средства разгона нельзя назвать абсолютно новыми, они существовали и раньше, хотя и показывали недостаточно стабильные и высокие результаты — разгон вручную практически всегда давал лучший результат. Однако, как отмечает Алексей Николайчук, автор MSI AfterBurner, технология Nvidia Scanner явно превосходит все предыдущие аналогичные средства. За время его испытаний этот инструмент ни разу не привел к краху ОС и всегда показывал стабильные (и достаточно высокие — порядка +10%-12%) частоты в результате. Да, GPU может зависать в процессе сканирования, но Nvidia Scanner всегда сам восстанавливает работоспособность и снижает частоты. Так что алгоритм реально неплохо работает и на практике.
Декодирование видеоданных и видеовыходы
Требования пользователей к поддержке устройств вывода постоянно растут — им хочется все бо́льших разрешений и максимального количества одновременно поддерживаемых мониторов. Самые продвинутые устройства имеют разрешение 8K (7680×4320 пикселей), требующее вчетверо большей пропускной способности по сравнению с 4K-разрешением (3820×2160), а энтузиасты компьютерных игр хотят максимально высокой частоты обновления информации на дисплеях — до 144 Гц и даже более.
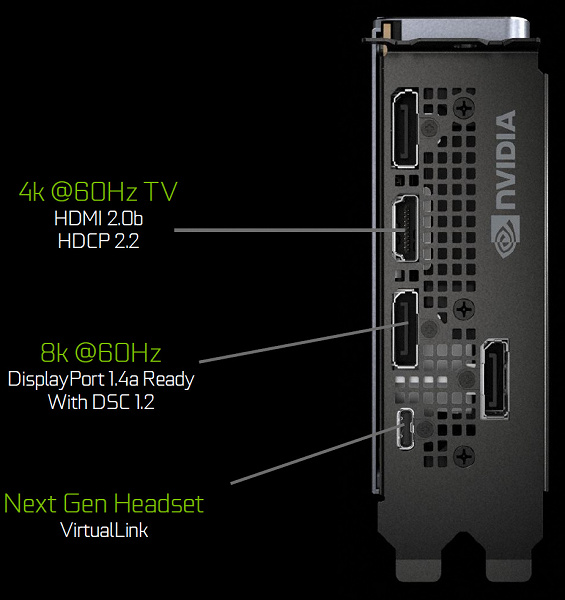
Графические процессоры семейства Turing содержат новый блок вывода информации, поддерживающий новые дисплеи с высоким разрешением, HDR и высокую частоту обновления. В частности, видеокарты линейки GeForce RTX имеют порты DisplayPort 1.4a, позволяющие вывести информацию на 8K-монитор с частотой обновления 60 Гц с поддержкой технологии VESA Display Stream Compression (DSC) 1.2, обеспечивающей высокую степень сжатия.

Платы Founders Edition содержат три выхода DisplayPort 1.4a, один разъем HDMI 2.0b (с поддержкой HDCP 2.2) и один VirtualLink (USB Type-C), предназначенный для будущих шлемов виртуальной реальности. Это новый стандарт подключения VR-шлемов, обеспечивающий передачу питания и высокую пропускную способность по USB-C. Такой подход значительно облегчает подключение шлемов. VirtualLink поддерживает четыре линии High BitRate 3 (HBR3) DisplayPort и линк SuperSpeed USB 3 для отслеживания движения шлема. Естественно, что использование разъема VirtualLink/USB Type-C требует дополнительного питания — до 35 Вт в плюс к объявленным 260 Вт типичного энергопотребления у GeForce RTX 2080 Ti.
Все решения семейства Turing поддерживают два 8K-дисплея при 60 Гц (требуется по одному кабелю на каждый), такое же разрешение также можно получить при подключении через установленный USB-C. Кроме этого, все Turing поддерживают полноценный HDR в конвейере вывода информации, включая tone mapping для различных мониторов — со стандартным динамическим диапазоном и широким.
Также новые GPU имеют улучшенный кодировщик видеоданных NVEnc, добавляющий поддержку компрессии данных в формате H.265 (HEVC) при разрешении 8K и 30 FPS. Новый блок NVEnc снижает требования к полосе пропускания до 25% при формате HEVC и до 15% при формате H.264. Также был обновлен и декодер видеоданных NVDec, получивший поддержку декодирования данных в формате HEVC YUV444 10-бит/12-бит HDR при 30 FPS, в формате H.264 при 8K-разрешении и в формате VP9 с 10-бит/12-бит данными.
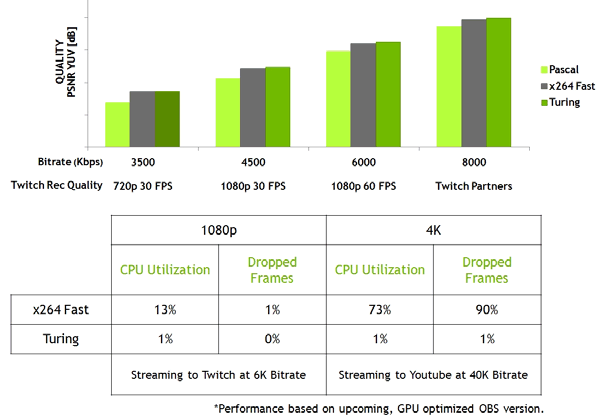
Семейство Turing еще и улучшает качество кодирования по сравнению с предыдущим поколением Pascal и даже по сравнению с программными кодировщиками. Кодировщик в новых GPU превосходит по качеству программный кодировщик x264, использующий быстрые (fast) настройки при значительно меньшем использовании ресурсов процессора. К примеру, стриминг видео в 4K-разрешении слишком тяжел для программных методов, а аппаратное кодирование видео на Turing способно исправить положение.
Графический ускоритель GeForce RTX 2080
Вместе с топовой видеокартой модели GeForce RTX 2080 Ti, компания Nvidia одновременно анонсировала и менее мощные варианты: RTX 2080 и RTX 2070, которые традиционно вызывают даже больший интерес публики, по сравнению с наиболее дорогой моделью, из-за лучшего соотношения цены и производительности. Рассмотрим средний вариант:
| Графический ускоритель GeForce RTX 2080 | |
|---|---|
| Кодовое имя чипа | TU104 |
| Технология производства | 12 нм FinFET |
| Количество транзисторов | 13,6 млрд. (у TU102 — 18,6 млрд.) |
| Площадь ядра | 545 мм² (у TU102 — 754 мм²) |
| Архитектура | унифицированная, с массивом процессоров для потоковой обработки любых видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | DirectX 12, с поддержкой уровня возможностей Feature Level 12_1 |
| Шина памяти | 256-битная: 8 независимых 32-битных контроллеров памяти с поддержкой памяти типа GDDR6 |
| Частота графического процессора | 1515 (1710/1800) МГц |
| Вычислительные блоки | 46 (из 48 физически имеющихся в GPU) потоковых мультипроцессоров, включающих 2944 (из 3072) CUDA-ядра для целочисленных расчетов INT32 и вычислений с плавающей запятой FP16/FP32 |
| Тензорные блоки | 368 (из 384) тензорных ядер для матричных вычислений INT4/INT8/FP16/FP32 |
| Блоки трассировки лучей | 46 (из 48) RT-ядер для расчета пересечения лучей с треугольниками и ограничивающими объемами BVH |
| Блоки текстурирования | 184 (из 192) блока текстурной адресации и фильтрации с поддержкой FP16/FP32-компонент и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) | 8 широких блоков ROP (64 пикселя) с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра |
| Поддержка мониторов | поддержка подключения по интерфейсам HDMI 2.0b и DisplayPort 1.4a |
| Спецификации референсной видеокарты GeForce RTX 2080 | |
|---|---|
| Частота ядра | 1515 (1710/1800) МГц |
| Количество универсальных процессоров | 2944 |
| Количество текстурных блоков | 184 |
| Количество блоков блендинга | 64 |
| Эффективная частота памяти | 14 ГГц |
| Тип памяти | GDDR6 |
| Шина памяти | 256-бит |
| Объем памяти | 8 ГБ |
| Пропускная способность памяти | 448 ГБ/с |
| Вычислительная производительность (FP16/FP32) | до 21,2/10,6 терафлопс |
| Производительность трассировки лучей | 8 гигалучей/с |
| Теоретическая максимальная скорость закраски | 109-115 гигапикселей/с |
| Теоретическая скорость выборки текстур | 315-331 гигатекселей/с |
| Шина | PCI Express 3.0 |
| Разъемы | один HDMI и три DisplayPort |
| Энергопотребление | до 215/225 Вт |
| Дополнительное питание | один 8-контактный и один 6-контактный разъемы |
| Число слотов, занимаемых в системном корпусе | 2 |
| Рекомендуемая цена | $699/$799 или 63990 руб. (Founders Edition) |
Как всегда, линейка GeForce RTX предлагает специальные продукты самой компании — так называемые Founders Edition. В этот раз при более высокой стоимости ($799 против $699 для рынка США — цены без учета налогов) они обладают и более привлекательными характеристиками. Приличный фабричный разгон у таких видеокарт есть изначально, а также видеокарты Founders Edition должны быть надежными и выглядят солидно благодаря отличному дизайну и грамотно подобранным материалам. А чтобы в надежности работы FE не было сомнений, каждая видеокарта тестируется на стабильность и обеспечивается трехлетней гарантией.

В видеокартах GeForce RTX Founders Edition применяется система охлаждения с испарительной камерой на всю длину печатной платы и с двумя вентиляторами для более эффективного охлаждения (по сравнению с одним вентилятором в предыдущих версиях FE). Длинная испарительная камера и большой двухслотовый алюминиевый радиатор обеспечивают довольно большую площадь рассеивания тепла, а тихие вентиляторы отводят горячий воздух в разные стороны, а не только наружу корпуса.
Система питания в GeForce RTX 2080 Founders Edition применяется весьма серьезная: 8-фазная схема iMon DrMOS (даже в GTX 1080 Ti Founders Edition была лишь 7-фазная dual-FET), поддерживающая новую динамическую систему управления питанием с более тонким контролем, улучшающая разгонные возможности видеокарты (о подробностях, связанных с разгоном, вы можете прочитать в обзоре RTX 2080 Ti). Для питания микросхем высокопроизводительной GDDR6-памяти установлена отдельная двухфазная схема.
Также FE-видеокарты Nvidia отличаются несколько большим уровнем энергопотребления, что обусловлено повышенными тактовыми частотами GPU. В этот раз партнерам компании было не так просто предложить еще более привлекательные варианты с фабричным разгоном, а пришлось делать экстремальные варианты с тремя разъемами дополнительного питания и усиленными системами охлаждения.
Архитектурные особенности
В модели видеокарты GeForce RTX 2080 применяется версия графического процессора TU104. Этот GPU имеет площадь 545 мм² (сравните с 754 мм² у TU102 и 610 мм² у топового чипа семейства Pascal — GP100) и содержит 13,6 млрд. транзисторов, по сравнению с 18,6 млрд. транзисторов у TU102 и 15,3 млрд. транзисторов у GP100. Так как новые GPU усложнились из-за появления аппаратных блоков, которых не было в Pascal, а техпроцессы применяются схожие, то по площади все новые чипы увеличились, если сравнивать схожие по наименованию модели.
Полный чип TU104 содержит шесть кластеров Graphics Processing Cluster (GPC), каждый из которых содержит четыре кластера Texture Processing Cluster (TPC), состоящих из одного движка PolyMorph Engine и пары мультипроцессоров SM. Соответственно, каждый SM состоит из: 64 CUDA-ядер, 256 КБ регистровой памяти и 96 КБ конфигурируемых L1-кэша и общей памяти, а также четырех блоков текстурирования TMU. Для нужд аппаратной трассировки лучей каждый мультипроцессор SM имеет также и по одному RT-ядру. Всего в полном чипе получается 48 мультипроцессоров SM, столько же RT-ядер, 3072 CUDA-ядер и 384 тензорных ядра.

Но это характеристики именно полного чипа TU104, различные модификации которого используются в моделях: GeForce RTX 2080, Tesla T4 и Quadro RTX 5000. В частности, рассматриваемая сегодня модель GeForce RTX 2080 основана на урезанной версии чипа с двумя аппаратно отключенными блоками SM. Соответственно, активными в ней остались: 2944 CUDA-ядра, 46 RT-ядра, 368 тензорных ядер и 184 блока текстурирования TMU.
А вот подсистема памяти в GeForce RTX 2080 полноценная, она содержит восемь 32-битных контроллеров памяти (256-бит в целом), при помощи которых GPU имеет доступ к 8 ГБ GDDR6-памяти, работающей на эффективной частоте в 14 ГГц, что дает пропускную способность в очень приличные 448 ГБ/с в итоге. К каждому контроллеру памяти привязаны по восемь блоков ROP и по 512 КБ кэш-памяти второго уровня. То есть, всего в чипе 64 блока ROP и 4 МБ L2-кэша.
Что касается тактовых частот нового графического процессора, то турбо-частота GPU у референсной карты равна 1710 МГц. Как и старшая модель GeForce RTX 2080 Ti, предлагаемая компанией со своего сайта видеокарта RTX 2080 Founders Edition имеет фабричный разгон до 1800 МГц — на 90 МГц больше, чем у референсных вариантов (хотя что такое референсные карты теперь — вопрос интересный).
По строению мультипроцессоров SM все чипы новой архитектуры Turing схожи друг с другом, в них появились новые типы вычислительных блоков: тензорные ядра и ядра ускорения трассировки лучей, а также были усложнены сами CUDA-ядра, в которых появилась возможность одновременного исполнения целочисленных вычислений и операций с плавающей запятой. Обо всех архитектурных изменениях мы очень подробно сообщали в обзоре GeForce RTX 2080 Ti, и очень советуем с ним ознакомиться.
Архитектурные изменения в вычислительных блоках привели к 50%-ному улучшению производительности шейдерных процессоров при равной тактовой частоте в играх в среднем. Также были улучшены технологии сжатия информации без потерь, архитектура Turing поддерживает новые техники компрессии, до 50% более эффективные по сравнению с алгоритмами в семействе чипов Pascal. Вместе с применением нового типа памяти GDDR6 это дает приличный прирост эффективной ПСП.
Это еще далеко не весь список нововведений и улучшений в Turing. Многие изменения в новой архитектуре нацелены на будущее, вроде mesh shading — новых шейдеров, ответственных за всю работу над геометрией, вершинами, тесселяцией и т. д., позволяющих значительно снизить зависимость от мощности CPU и во много раз увеличить количество объектов в сцене. Или взять Variable Rate Shading (VRS) — шейдинг с переменным количеством сэмплов, позволяющий оптимизировать рендеринг при помощи переменного количества сэмплов закраски, упрощая шейдинг лишь там, где это оправдано.
Отметим внедрение высокопроизводительного интерфейса NVLink второй версии, который используется для объединения GPU в том числе и для работы над изображением в режиме SLI. Топовый чип TU102 имеет два порта NVLink второго поколения, а в TU104 есть лишь один такой порт, но его пропускной способности в 50 ГБ/с хватит для передачи кадрового буфера с разрешением 8К в режиме многочипового рендеринга AFR от одного GPU к другому. Такая скорость позволяет использовать локальную видеопамять соседнего GPU как свою собственную полностью автоматически, без сложного программирования.
Графические процессоры семейства Turing также содержат новый блок вывода информации, поддерживающий дисплеи с высоким разрешением, с HDR и высокой частотой обновления. В частности, GeForce RTX имеют порты DisplayPort 1.4a, позволяющие вывести информацию на 8K-монитор с частотой обновления 60 Гц с поддержкой технологии VESA Display Stream Compression (DSC) 1.2, обеспечивающей высокую степень сжатия.
Платы Founders Edition содержат три таких выхода DisplayPort 1.4a, один разъем HDMI 2.0b (с поддержкой HDCP 2.2) и один VirtualLink (USB Type-C), предназначенный для будущих шлемов виртуальной реальности. Это новый стандарт подключения VR-шлемов, обеспечивающий передачу питания и высокую пропускную способность по разъему USB-C.
Все решения семейства Turing поддерживают два 8K-дисплея при 60 Гц (требуется по одному кабелю на каждый), такое же разрешение также можно получить при подключении через установленный USB-C. Кроме этого, все Turing поддерживают полноценный HDR в конвейере вывода информации, включая tone mapping для различных мониторов — со стандартным динамическим диапазоном и расширенным.
Новые GPU содержат улучшенный кодировщик видеоданных NVEnc, добавляющий поддержку сжатия данных в формате H.265 (HEVC) при разрешении 8K и 30 FPS. Такой блок NVEnc снижает требования к полосе пропускания до 25% при формате HEVC и до 15% при формате H.264. Также был обновлен и декодер видеоданных NVDec, получивший поддержку декодирования данных в формате HEVC YUV444 10-бит/12-бит HDR при 30 FPS, в формате H.264 при 8K-разрешении и в формате VP9 с 10-бит/12-бит данными.
Графический ускоритель GeForce RTX 2070
Вместе с топовой и средней моделей видеокарт, компания Nvidia анонсировала и самую доступную модель — GeForce RTX 2070, на которую рассчитывают многие любители игр из-за сравнительно низкой цены и хорошего соотношения цены и производительности. Достаточно ли мощности для современных игр с применением трассировки лучей у младшей модели?
| Графический ускоритель GeForce RTX 2070 | |
|---|---|
| Кодовое имя чипа | TU106 |
| Технология производства | 12 нм FinFET |
| Количество транзисторов | 10,8 млрд (у TU104 — 13,6 млрд) |
| Площадь ядра | 445 мм² (у TU104 — 545 мм²) |
| Архитектура | унифицированная, с массивом процессоров для потоковой обработки любых видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | DirectX 12, с поддержкой уровня возможностей Feature Level 12_1 |
| Шина памяти | 256-битная: 8 независимых 32-битных контроллеров памяти с поддержкой памяти типа GDDR6 |
| Частота графического процессора | 1410 (1620/1710) МГц |
| Вычислительные блоки | 36 потоковых мультипроцессоров, включающих 2304 CUDA-ядра для целочисленных расчетов INT32 и вычислений с плавающей запятой FP16/FP32 |
| Тензорные блоки | 288 тензорных ядер для матричных вычислений INT4/INT8/FP16/FP32 |
| Блоки трассировки лучей | 36 RT-ядер для расчета пересечения лучей с треугольниками и ограничивающими объемами BVH |
| Блоки текстурирования | 144 блока текстурной адресации и фильтрации с поддержкой FP16/FP32-компонент и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) | 8 широких блоков ROP (64 пикселя) с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра |
| Поддержка мониторов | поддержка подключения по интерфейсам HDMI 2.0b и DisplayPort 1.4a |
| Спецификации референсной видеокарты GeForce RTX 2070 | |
|---|---|
| Частота ядра | 1410 (1620/1710) МГц |
| Количество универсальных процессоров | 2304 |
| Количество текстурных блоков | 144 |
| Количество блоков блендинга | 64 |
| Эффективная частота памяти | 14 ГГц |
| Тип памяти | GDDR6 |
| Шина памяти | 256-бит |
| Объем памяти | 8 ГБ |
| Пропускная способность памяти | 448 ГБ/с |
| Вычислительная производительность (FP16/FP32) | до 15,8/7,9 терафлопс |
| Производительность трассировки лучей | 6 гигалучей/с |
| Теоретическая максимальная скорость закраски | 104—109 гигапикселей/с |
| Теоретическая скорость выборки текстур | 233—246 гигатекселей/с |
| Шина | PCI Express 3.0 |
| Разъемы | один HDMI и три DisplayPort |
| Энергопотребление | до 175/185 Вт |
| Дополнительное питание | один 8-контактный и один 6-контактный разъемы |
| Число слотов, занимаемых в системном корпусе | 2 |
| Рекомендуемая цена | $499/$599 или 42/49 тысяч рублей |
Founders Edition в этот раз при несколько более высокой стоимости ($599 против $499 для рынка США — цены без учета налогов) они обладают и более привлекательными характеристиками. У таких видеокарт есть изначально весьма приличный фабричный разгон, а также видеокарты Founders Edition должны быть надежными и они выглядят очень солидно из-за строгого дизайна и специально подобранных материалов.
Чтобы в надежности работы таких FE-видеокарт не оставалось сомнений, каждая плата тестируется на стабильность и обеспечивается трехлетней гарантией. Что оказалось весьма полезным делом, так как в некоторых из видеокарт первых партий топового решения допустили брак — но все вышедшие из строя такие карты без проблем заменяются по гарантии.
В видеокартах GeForce RTX Founders Edition применяется оригинальная система охлаждения с испарительной камерой на всю длину печатной платы и с двумя вентиляторами — для более эффективного охлаждения (по сравнению с одним вентилятором в предыдущих версиях FE). Длинная испарительная камера и большой двухслотовый алюминиевый радиатор обеспечивают довольно большую площадь рассеивания тепла, а тихие вентиляторы отводят горячий воздух в разные стороны, а не только наружу корпуса. В последнем есть и плюс и минус. К примеру, при очень плотном размещении видеокарт (не через слот, а в каждом) они могут перегреваться, ведь это — не самые обычные условия работы для GeForce.
Кроме описанных отличий, FE-видеокарты отличаются и несколько большим уровнем энергопотребления, что обусловлено повышенными тактовыми частотами GPU для таких вариантов. В этот раз партнерам компании приходится предлагать варианты с еще большим фабричным разгоном — экстремальные варианты с лучшими характеристиками по дополнительному питанию, а также усиленными системами охлаждения.
Архитектурные особенности
Младшая модель видеокарты GeForce RTX 2070 основана на графическом процессоре TU106. Этот GPU используется только для этой платы и имеет площадь 445 мм² (сравните с 545 мм² у TU104, на котором сделан RTX 2080, и с 471 мм² у лучшего игрового чипа семейства Pascal — GP102, основе GeForce GTX 1080 Ti), содержит 10,8 млрд транзисторов, по сравнению с 13,6 млрд транзисторов у среднего TU104 и с 12 млрд транзисторов у GP102 — основе GTX 1080 Ti.
Полная версия чипа TU106 содержит три кластера Graphics Processing Cluster (GPC), каждый из которых содержит по шесть кластеров Texture Processing Cluster (TPC), состоящих из одного движка PolyMorph Engine и пары мультипроцессоров SM. Соответственно, каждый SM состоит из: 64 CUDA-ядер, 256 КБ регистровой памяти и 96 КБ конфигурируемых L1-кэша и общей памяти, а также четырех блоков текстурирования TMU. Для нужд аппаратной трассировки лучей каждый мультипроцессор SM имеет также и по одному RT-ядру. Всего чип включает 36 мультипроцессоров SM, столько же RT-ядер, 2304 CUDA-ядер и 288 тензорных ядер.

Рассматриваемая нами модель GeForce RTX 2070 основана на полной версии этого чипа, поэтому все указанные характеристики соответствуют также и ей. Подсистема памяти аналогична той, что мы видели в TU104 и GeForce RTX 2080, она содержит восемь 32-битных контроллеров памяти (256-бит в целом), при помощи которых GPU имеет доступ к 8 ГБ GDDR6-памяти, работающей на эффективной частоте в 14 ГГц, что дает пропускную способность в очень приличные 448 ГБ/с в итоге. К каждому контроллеру памяти привязаны по восемь блоков ROP и по 512 КБ кэш-памяти второго уровня. То есть, всего в чипе 64 блока ROP и 4 МБ L2-кэша.
Что касается тактовых частот нового графического процессора в составе младшей модели линейки GeForce RTX, то турбо-частота GPU у референсного варианта (не путать с FE!) карты составляет 1620 МГц. Как и две другие модели линейки, предлагаемая компанией со своего сайта видеокарта RTX 2070 Founders Edition имеет фабричный разгон до 1710 МГц — на 90 МГц больше, чем у стандартных вариантов от производителей видеокарт.
По строению мультипроцессоров SM все чипы новой архитектуры Turing схожи друг с другом, в них появились новые типы вычислительных блоков: тензорные ядра и ядра ускорения трассировки лучей, а также были усложнены сами CUDA-ядра, в которых появилась возможность одновременного исполнения целочисленных вычислений и операций с плавающей запятой. Обо всех важных изменениях мы очень подробно сообщали в обзоре GeForce RTX 2080 Ti, и очень советуем ознакомиться с этим большим и важным материалом.
Архитектурные изменения в вычислительных блоках привели к 50%-ному улучшению производительности шейдерных процессоров при равной тактовой частоте в среднем. Также были улучшены технологии сжатия информации без потерь, архитектура Turing поддерживает новые техники компрессии, также до 50% более эффективные, по сравнению с алгоритмами в семействе чипов Pascal. Вместе с применением нового типа памяти GDDR6 это дает приличный прирост эффективной ПСП. Хотя конкретно у RTX 2070 пропускной способности памяти и так довольно много — не меньше, чем у RTX 2080.
Многие изменения в новой архитектуре Turing нацелены на будущее, вроде mesh shading — новых типов шейдеров, ответственных за всю работу над геометрией, вершинами, тесселяцией и т. д. Если вкратце, то они позволяют значительно снизить зависимость от мощности CPU и во много раз увеличить количество объектов в сцене.
Очень важно отметить, что поддержки высокопроизводительного интерфейса NVLink второй версии, который используется для объединения GPU в том числе и для работы над изображением в режиме SLI, конкретно в младшем чипе линейки TU106 нет, хотя в TU102 в наличии два порта NVLink, а в TU104 — один. Похоже, в компании Nvidia таким образом разделяют рынки, предлагая заинтересованным в SLI-системах приобретать более дорогие варианты графических карт.
А вот новый блок вывода информации, поддерживающий дисплеи с высоким разрешением, с HDR и высокой частотой обновления, есть во всех графических процессорах семейства Turing, в том числе и в TU106. Все GeForce RTX имеют порты DisplayPort 1.4a, позволяющие вывести информацию на 8K-монитор с частотой обновления 60 Гц с поддержкой технологии VESA Display Stream Compression (DSC) 1.2, обеспечивающей высокую степень сжатия.
Платы Founders Edition содержат три таких выхода DisplayPort 1.4a, один разъем HDMI 2.0b (с поддержкой HDCP 2.2) и один VirtualLink (USB Type-C), предназначенный для будущих шлемов виртуальной реальности. Это новый стандарт подключения VR-шлемов, обеспечивающий передачу питания и высокую пропускную способность по разъему USB-C.
Все решения семейства Turing поддерживают два 8K-дисплея при 60 Гц (требуется по одному кабелю на каждый), такое же разрешение также можно получить при подключении через установленный USB-C. Кроме этого, все Turing поддерживают полноценный HDR в конвейере вывода информации, включая tone mapping для различных мониторов — со стандартным динамическим диапазоном и расширенным.
Все новые GPU также содержат улучшенный кодировщик видеоданных NVEnc, добавляющий поддержку сжатия данных в формате H.265 (HEVC) при разрешении 8K и 30 FPS. Такой блок NVEnc снижает требования к полосе пропускания до 25% при формате HEVC и до 15% при формате H.264. Также был обновлен и декодер видеоданных NVDec, получивший поддержку декодирования данных в формате HEVC YUV444 10-бит/12-бит HDR при 30 FPS, в формате H.264 при 8K-разрешении и в формате VP9 с 10-бит/12-бит данными.
Графический ускоритель GeForce RTX 2060
Ещё чуть позже настало время самой младшей модели в новом семействе – GeForce RTX 2060. С момента анонса старших видеокарт на Gamescom прошло почти полгода, Nvidia первым снимала сливки с дорогих продуктов, когда одна за одной были выпущены модели GeForce RTX 2080 Ti, GeForce RTX 2080 и GeForce RTX 2070, а бюджетную (относительно) видеокарту придержала.
Неудивительно, что появился и некоторый негатив, связанный с выходом дорогих решений линейки GeForce RTX. И речь не только о топовой GeForce RTX 2080 Ti, которая хоть и имеет потрясающую производительность и новую функциональность, но выделяется очень высокой ценой, которая отпугнула многих пользователей. Остальные решения семейства Turing из первой тройки не блистали доступностью розничных цен. Конечно, повышенным ценам есть вполне логичные объяснения, но. мотивацию для покупки они добавляют не всегда. Многие потенциальные покупатели ждали более доступной видеокарты.
И вот она появилась — в начале января 2019 года глава компании Nvidia анонсировал GeForce RTX 2060 на отраслевой конференции CES. К слову, даже сам Дженсен Хуанг признал, что стоимость первых трех выпущенных GeForce RTX слишком высока для массового распространения новых Turing с революционными функциями аппаратной трассировки лучей и ускорения тензорных вычислений. А ведь Nvidia сама кровно заинтересована в том, чтобы GPU с новыми функциями завоевывали рынок. Но так как это вряд ли возможно с ценами на видеокарты от $500 и выше, то на рынок вышла и GeForce RTX 2060 за $349.
Эта цена также превышает то значение, к которому мы привыкли для GPU этого уровня, ведь на момент своего анонса та же GeForce GTX 1060 стоила на сотню дешевле. Но в любом случае, GeForce RTX 2060 стала самой доступной моделью с аппаратным ускорением трассировки лучей и глубокого обучения. Она интересна еще и потому, что должна дать более ощутимый прирост производительности при смене поколения GPU. Эта модель стала не просто наиболее доступным, но и самым выгодным решением из всего нового семейства.
| Графический ускоритель GeForce RTX 2060 | |
|---|---|
| Кодовое имя чипа | TU106 |
| Технология производства | 12 нм FinFET |
| Количество транзисторов | 10,8 млрд |
| Площадь ядра | 445 мм² |
| Архитектура | унифицированная, с массивом процессоров для потоковой обработки любых видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | DirectX 12, с поддержкой уровня возможностей Feature Level 12_1 |
| Шина памяти | 192-битная: 6 (из 8 имеющихся) независимых 32-битных контроллеров памяти с поддержкой памяти типа GDDR6 |
| Частота графического процессора | 1365 (1680) МГц |
| Вычислительные блоки | 30 (из 36 имеющихся) потоковых мультипроцессоров, включающих 1920 (из 2304) CUDA-ядер для целочисленных расчетов INT32 и вычислений с плавающей запятой FP16/FP32 |
| Тензорные блоки | 240 (из 288) тензорных ядер для матричных вычислений INT4/INT8/FP16/FP32 |
| Блоки трассировки лучей | 30 (из 36) RT-ядер для расчета пересечения лучей с треугольниками и ограничивающими объемами BVH |
| Блоки текстурирования | 120 (из 144) блоков текстурной адресации и фильтрации с поддержкой FP16/FP32-компонент и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) | 6 (из  широких блоков ROP (48 пикселей) с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра широких блоков ROP (48 пикселей) с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра |
| Поддержка мониторов | поддержка подключения по интерфейсам HDMI 2.0b и DisplayPort 1.4a |
| Спецификации референсной видеокарты GeForce RTX 2060 | |
|---|---|
| Частота ядра | 1365 (1680) МГц |
| Количество универсальных процессоров | 1920 |
| Количество текстурных блоков | 120 |
| Количество блоков блендинга | 48 |
| Эффективная частота памяти | 14 ГГц |
| Тип памяти | GDDR6 |
| Шина памяти | 192-бит |
| Объем памяти | 6 ГБ |
| Пропускная способность памяти | 336 ГБ/с |
| Вычислительная производительность (FP16/FP32) | до 12,9/6,5 терафлопс |
| Производительность трассировки лучей | 5 гигалучей/с |
| Теоретическая максимальная скорость закраски | 81 гигапиксель/с |
| Теоретическая скорость выборки текстур | 202 гигатекселя/с |
| Шина | PCI Express 3.0 |
| Разъемы | один HDMI, один DVI и два DisplayPort |
| Энергопотребление | до 160 Вт |
| Дополнительное питание | один 8-контактный разъем |
| Число слотов, занимаемых в системном корпусе | 2 |
| Рекомендуемая цена | $349 (31 990 рублей) |
Как и в случае старших моделей, для RTX 2060 предлагается и специальный продукт от самой компании — так называемый Founders Edition. В этот раз FE-издание не отличается ни иной стоимостью, ни более привлекательными частотными характеристиками. Nvidia убрала фабричный разгон для FE-варианта GeForce RTX 2060, и все недорогие карты должны иметь схожие характеристики по частоте — GPU работает на турбо-частоте в 1680 МГц, а GDDR6-память имеет частоту в 14 ГГц.

Видеокарты Founders Edition должны быть довольно надежными, да и выглядят они солидно из-за строгого дизайна и грамотно подобранных материалов. В RTX 2060 применяется та же система охлаждения с испарительной камерой на всю длину печатной платы и двумя вентиляторами — для более эффективного охлаждения (по сравнению с одним вентилятором в предыдущих версиях). Длинная испарительная камера и большой двухслотовый алюминиевый радиатор обеспечивают большую площадь рассеивания тепла, а тихие вентиляторы отводят горячий воздух в разные стороны, а не только наружу корпуса.
Видеокарты модели GeForce RTX 2060 поступили в продажу с 15 января в виде Nvidia Founders Edition и решениях партнеров, включая компании Asus, Colorful, EVGA, Gainward, Galaxy, Gigabyte, Innovision 3D, MSI, Palit, PNY и Zotac — с собственным дизайном и характеристиками. А чтобы еще больше улучшить привлекательность новинки, Nvidia объявила о комплектации видеокарты игрой Anthem или Battlefield V — на выбор пользователя, купившего GeForce RTX 2060 или готовую систему на его основе.
Архитектурные особенности
В случае модели GeForce RTX 2060, многое пришлось делать совсем не так, как в предыдущих поколениях. Это связано как с добавлением специализированных блоков, серьезно усложнивших GPU, так и с отсутствием серьезной смены техпроцесса. Вот если бы графические процессоры Turing вышли сразу на техпроцессе 7 нм (правда, позже на год), то вполне возможно, что Nvidia бы даже удержала цены в привычных диапазонах для всех решений линейки. Но не в этот раз.
Видеокарты уровня x60 (260, 460, 660, 760, 1060 и другие) всегда были основаны на отдельной модели GPU средней сложности, оптимизированного для этой самой золотой середины. А в нынешнем поколении это тот же чип, что и для RTX 2070, но урезанный по количеству исполнительных блоков. Давайте сравним характеристики нескольких моделей видеокарт Nvidia двух последних поколений:
| RTX 2070 | GTX 1070 Ti | GTX 1070 | RTX 2060 | GTX 1060 | |
|---|---|---|---|---|---|
| Кодовое имя GPU | TU106 | GP104 | GP104 | TU106 | GP106 |
| Кол-во транзисторов, млрд | 10,8 | 7,2 | 7,2 | 10,8 | 4,4 |
| Площадь кристалла, мм² | 445 | 314 | 314 | 445 | 200 |
| Базовая частота, МГц | 1410 | 1607 | 1506 | 1365 | 1506 |
| Турбо-частота, МГц | 1620 (1710) | 1683 | 1683 | 1680 | 1708 |
| CUDA-ядра, шт | 2304 | 2432 | 1920 | 1920 | 1280 |
| Производительность FP32, GFLOPS | 7465 (7880) | 8186 | 6463 | 6221 | 3855 |
| Тензорные ядра, шт | 288 | 0 | 0 | 240 | 0 |
| RT-ядра, шт | 36 | 0 | 0 | 30 | 0 |
| Блоки ROP, шт | 64 | 64 | 64 | 48 | 48 |
| Блоки TMU, шт | 144 | 152 | 120 | 120 | 80 |
| Объем видеопамяти, ГБ | 8 | 8 | 8 | 6 | 6 |
| Шина памяти, бит | 256 | 256 | 256 | 192 | 192 |
| Тип памяти | GDDR6 | GDDR5 | GDDR5 | GDDR6 | GDDR5 |
| Частота памяти, ГГц | 14 | 8 | 8 | 14 | 8 |
| ПСП памяти, ГБ/с | 448 | 256 | 256 | 336 | 192 |
| Энергопотребление TDP, Вт | 175 (185) | 180 | 150 | 160 | 120 |
| Рекомендованная цена, $ | 499 (599) | 449 | 379 | 349 | 249(299) |
По таблице хорошо видно, что RTX 2060 основан не на каком-то новом GPU, а на урезанном TU106, известном нам по RTX 2070, хотя раньше для x60-видеокарт применялись чипы меньшей сложности и размера (и, соответственно, меньшей цены). Сравнение пары RTX 2060 и GTX 1060 поражает: новый чип сложнее более чем в два раза, да и кристалл по площади крупнее более чем вдвое. Это все как раз объясняется практически неизменным техпроцессом (12 нм — это совсем чуть-чуть измененный 16 нм) при всех усложнениях, в том числе в виде тензорных и RT-ядер.
И чтобы не создавать внутреннюю конкуренцию среди своих продуктов, Nvidia пришлось сильно порезать чип для RTX 2060 по многим статьям, оставив лишь 30 из имеющихся 36 мультипроцессоров SM, которые включают CUDA-ядра, текстурные блоки, RT-ядра и тензорные ядра. То есть RTX 2060 по активным вычислительным блокам меньше RTX 2070 на 20%.
Чтобы еще больше подчеркнуть разницу между решениями разных ценовых уровней, также решили сильно урезать и подсистему памяти и ее кэширования: ширина шины снизилась с 256 бит до 192 бит, количество блоков ROP — с 64 до 48, заодно и объем видеопамяти урезали с 8 ГБ до 6 ГБ, что обиднее всего, так как для сохранения достаточно высокой ПСП оставили быструю GDDR6-память, работающую на частоте 14 ГГц. Посмотрим на схеме, что же получилось в итоге:

Урезанная версия чипа TU106 в модификации для RTX 2060 содержит три кластера Graphics Processing Cluster (GPC), но количество кластеров Texture Processing Cluster (TPC), состоящих из движков PolyMorph Engine и мультипроцессоров SM, изменилось — шесть TPC тут неактивны. Каждый SM состоит из: 64 CUDA-ядер, четырех блоков текстурирования TMU, восьми тензорных и одного RT-ядра, поэтому всего в урезанном чипе остались активными 30 мультипроцессоров SM, столько же RT-ядер, 1920 CUDA-ядер и 240 тензорных ядер.
Наверное, условный «TU108» с уменьшенным количеством всех исполнительных блоков, имеющий меньшие сложность, размер и энергопотребление, был бы выгоднее для Nvidia, но не на этой стадии развития микропроцессорного производства. Зато для производства GeForce RTX 2060 можно отправить большую часть отбраковки от RTX 2070.
Что же касается тактовых частот графического процессора в составе младшей модели линейки GeForce RTX, то турбо-частота GPU у референсного варианта (он соответствует FE-изданию в этот раз) карты составляет 1680 МГц. Видеопамять стандарта GDDR6 работает на частоте 14 ГГц, что дает нам пропускную способность в 336 ГБ/с.
У многих пользователей может появиться резонный вопрос — а «потянет» ли самый слабый GPU с поддержкой ускорения трассировки лучей соответствующие игры? Видеокарта модели RTX 2060 имеет 30 RT-ядер и обеспечивает производительность до 5 гигалучей/с, что ненамного хуже 6 гигалучей/с у той же RTX 2070. За все будущие игровые проекты ответить сложно, но конкретно в игре Battlefield V вполне можно играть в Full HD-разрешении с ультра-настройками и трассировкой лучей, получая 60 FPS. Более высокое разрешение, конечно, новинка уже не потянет — да и вообще, игра многопользовательская, в ней не до особых красот, честно говоря.
В общем, новый GPU должен обеспечивать где-то 75%-80% от мощности GeForce RTX 2070, что довольно неплохо — вероятно, даже не только для Full HD-разрешения, но и для WQHD (если хватит 6 ГБ памяти в каждом конкретном случае), а вот для 4K уже вряд ли. По данным Nvidia, новый GeForce RTX 2060 на 60% быстрее GTX 1060 из предыдущего поколения, и очень близок к GeForce GTX 1070 Ti, а это — очень хороший уровень производительности.
Графические ускорители GeForce GTX 1660 Ti и GTX 1660
Выход видеокарт Nvidia, основанных на графической архитектуре Turing, стал важной вехой для 3D-графики реального времени. Первые решения линейки GeForce RTX были представлены компанией еще осенью 2018 года, а в феврале пришло время и для менее дорогих GPU новой архитектуры. Графический процессор TU116 стал первым среди бюджетного подсемейства Turing, который предназначен для решений с ценами ниже $300, и первой видеокартой на основе этого чипа стала модель GeForce GTX 1660 Ti, предлагаемая по цене $279.
При подготовке среднебюджетных решений семейства Turing возможность оставить в них RT-ядра и тензорные ядра была лишь теоретической — уж слишком сильно они усложняют чипы. Задолго до выхода GPU этого уровня распространялись слухи о том, что они лишатся специализированных блоков для аппаратного ускорения трассировки лучей и глубокого обучения, так и получилось в итоге: модель GeForce GTX 1660 Ti вышла с приставкой GTX, а не RTX, и этот GPU не включает в себя RT-ядра и тензорные ядра, с которыми мы познакомились в предыдущих решениях семейства.
Оно и неудивительно, ведь в сильно ограниченном транзисторном бюджете этой ценовой категории было бы невозможно предложить достаточный уровень производительности таких блоков, так как даже GeForce RTX 2060 с трудом справляется с этими задачами, и не в самых высоких разрешениях. А добавление тех же RT-ядер к GPU не имеет смысла без соответствующего уровня производительности обычных CUDA-ядер. С тензорными ядрами вопрос сложнее, и мы его подробно рассмотрим далее. В любом случае, факт в том, что GeForce GTX 1660 Ti не имеет поддержки аппаратного ускорения трассировки лучей и глубокого обучения и фокусируется на достижении максимально возможной производительности в существующих играх в рамках транзисторного бюджета.
В архитектуре Turing инженеры компании Nvidia внедрили и множество других улучшений по сравнению с архитектурой Pascal: одновременное исполнение операций с плавающей запятой FP32 и целочисленных INT32, значительно измененную и улучшенную систему кэширования данных и несколько новых технологий рендеринга: программируемый конвейер обработки геометрии, переменную частоту затенения, затенение в текстурном пространстве, поддержку последних версий технологий DirectX 12, относящихся к уровню возможностей Feature Level 12_1.
Благодаря всем улучшениям мультипроцессоров Turing, по производительности и энергоэффективности видеокарта на базе TU116 превосходит аналогичные GPU из предыдущих семейств. Новый GPU особенно хорош в современных играх, использующих сложные шейдеры. Модель GeForce GTX 1660 Ti в среднем в 2-3 раза быстрее GeForce GTX 960 и до полутора раз быстрее GeForce GTX 1060 6GB в самых требовательных играх последнего времени.
Да и в сверхпопулярных многопользовательских проектах, таких как PUBG, Apex Legends, Fortnite и Call of Duty Black Ops 4, новый GPU позволяет получить 120 FPS и более при высоких настройках качества в Full HD-разрешении. Это довольно важно для динамичных сетевых шутеров, тогда как на видеокартах уровня GeForce GTX 960 игроки получают в тех же условиях лишь 50-60 FPS. А для таких игр высокая частота кадров довольно важна, ведь привычная мерка в 60 FPS в них не является пределом мечтаний — при подключении мониторов с частотой обновления 120-144 Гц удвоенный прирост плавности может принести и повышенную эффективность в сражениях.
В общем, GeForce GTX 1660 Ti за его цену даже чисто на бумаге выглядит весьма интересным решением для обновления видеоподсистемы у тех игроков, кто еще не сделал апгрейда на Pascal. На сегодняшний день почти две трети (64%) игроков имеют видеокарты уровня GeForce GTX 960 или ниже, а новинка предлагает уровень производительности вдвое-втрое выше этого устаревшего GPU практически во всех играх и поэтому довольно привлекательна для апгрейда.
| Графический ускоритель GeForce GTX 1660 Ti | |
|---|---|
| Кодовое имя чипа | TU116 |
| Технология производства | 12 нм FinFET |
| Количество транзисторов | 6,6 млрд (у GP106 — 4,4 млрд) |
| Площадь ядра | 284 мм² (у GP106 — 200 мм²) |
| Архитектура | унифицированная, с массивом процессоров для потоковой обработки любых видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | DirectX 12, с поддержкой уровня возможностей Feature Level 12_1 |
| Шина памяти | 192-битная: 6 независимых 32-битных контроллеров памяти с поддержкой памяти типов GDDR5 и GDDR6 |
| Частота графического процессора | 1500 (1770) МГц |
| Вычислительные блоки | 24 потоковых мультипроцессора, включающих 1536 CUDA-ядер для целочисленных расчетов INT32 и вычислений с плавающей запятой FP16/FP32 |
| Блоки текстурирования | 96 блоков текстурной адресации и фильтрации с поддержкой FP16/FP32-компонент и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) | 6 широких блоков ROP (48 пикселей) с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра |
| Поддержка мониторов | поддержка подключения по интерфейсам HDMI 2.0b и DisplayPort 1.4a |
| Спецификации референсной видеокарты GeForce GTX 1660 Ti | |
|---|---|
| Частота ядра | 1500 (1770) МГц |
| Количество универсальных процессоров | 1536 |
| Количество текстурных блоков | 96 |
| Количество блоков блендинга | 48 |
| Эффективная частота памяти | 12 ГГц |
| Тип памяти | GDDR6 |
| Шина памяти | 192-бит |
| Объем памяти | 6 ГБ |
| Пропускная способность памяти | 288 ГБ/с |
| Вычислительная производительность (FP16/FP32) | 11,0/5,5 терафлопс |
| Теоретическая максимальная скорость закраски | 85 гигапикселей/с |
| Теоретическая скорость выборки текстур | 170 гигатекселей/с |
| Шина | PCI Express 3.0 |
| Разъемы | в зависимости от видеокарты |
| Энергопотребление | до 120 Вт |
| Дополнительное питание | один 8-контактный разъем |
| Число слотов, занимаемых в системном корпусе | 2 |
| Рекомендуемая цена | $279 (22 990 рублей) |
| Спецификации референсной видеокарты GeForce GTX 1660 | |
|---|---|
| Частота ядра | 1530 (1785) МГц |
| Количество универсальных процессоров | 1408 |
| Количество текстурных блоков | 88 |
| Количество блоков блендинга | 48 |
| Эффективная частота памяти | 8 ГГц |
| Тип памяти | GDDR5 |
| Шина памяти | 192 бит |
| Объем памяти | 6 ГБ |
| Пропускная способность памяти | 192 ГБ/с |
| Вычислительная производительность (FP16/FP32) | 10,0/5,0 терафлопс |
| Теоретическая максимальная скорость закраски | 86 гигапикселей/с |
| Теоретическая скорость выборки текстур | 157 гигатекселей/с |
| Шина | PCI Express 3.0 |
| Разъемы | в зависимости от видеокарты |
| Энергопотребление | до 120 Вт |
| Дополнительное питание | один 8-контактный разъем |
| Число слотов, занимаемых в системном корпусе | 2 |
| Рекомендуемая цена | $219 (17 990 рублей) |
Модель GTX 1660 Ti открывает новое семейство видеокарт — серию GeForce GTX 16, которая отличается от серии GeForce RTX 20 и суффиксом, и численными значениями серии. Если с заменой RTX на GTX все понятно (карты GTX не имеют поддержки технологий, которые есть у RTX), то меньшее значение для серии выглядит немного странно — видимо, в Nvidia решили не давать этим картам серию 20, чтобы сильнее разделить серии из маркетинговых соображений. А вот почему было выбрано именно число 16 — не очень понятно (кроме очевидного факта, что оно между 10 и 20). Почему не 15, например?
Интересно, что видеокарта GTX 1660 Ti не имеет публичного референсного варианта, равно как и Founders Edition. Партнеры компании делают собственные дизайны карт на основе внутреннего эталонного дизайна карты Nvidia, и в этом случае мы сразу же увидели в продаже множество вариантов карт с различными характеристиками и системами охлаждения.
GeForce GTX 1660 Ti поступила в продажу по цене от $279, то есть на $30 дороже GTX 1060 6GB, которую она и заменяет в линейке компании. Конечно же, это дешевле, чем $349 за RTX 2060, но такое решение снова выглядит как повышение цен на GPU определенного ценового диапазона. Если в случае с RTX оно было оправдано новыми технологиями, то в случае с GTX 1660 Ti это просто повышение цены для среднебюджетного GPU.
В новом GPU инженеры решили использовать проверенную временем 192-битную шину памяти, которая ограничивает возможные варианты объема видеопамяти значениями 6 ГБ или 12 ГБ. Второй вариант крутоват для модели этого ценового сегмента, особенно учитывая дорогую GDDR6-память, поэтому пришлось ограничиться 6 ГБ. Как и в случае RTX 2060, это кажется компромиссным решением, хотелось бы иметь 8 ГБ. Впрочем, в реальном применении в течение актуального жизненного цикла GPU, с учетом того, что он рассчитан на разрешение Full HD, случаи с жесткой нехваткой видеопамяти вряд ли будут возникать слишком часто.
Еще одной важной характеристикой любого GPU является потребление энергии, и тут Nvidia смогла вместить GTX 1660 Ti в тот же теплопакет 120 Вт, что и GTX 1060 6GB. Видимо, за это во многом стоит поблагодарить отказ от технологий RTX, так как старшие чипы Turing потребляют больше энергии, чем их предшественники из семейства Pascal.
GeForce GTX 1660 Ti вышла в продажу 22 февраля 2019 года и партнеры компании Nvidia сразу же предложили широкий набор различных модификаций этой видеокарты на основе их собственного дизайна, включая фабрично разогнанные варианты с самыми разными системами охлаждения, имеющими от одного до трех вентиляторов:

Типичная видеокарта модели GeForce GTX 1660 Ti довольствуется одним 8-контактным разъемом дополнительного питания PCI Express, а вот количество и тип разъемов вывода информации на дисплеи зависит исключительно от конкретной карты. Сам по себе GPU поддерживает все те же разъемы и стандарты DVI, HDMI, DisplayPort и VirtualLink, что и более мощные решения семейства Turing.
Почти сразу на основе урезанной версии чипа TU116 у Nvidia в скором времени вышло и менее дорогое решение семейства – GeForce GTX 1660. Эта модель имеет рекомендованную цену в $219 — среднюю между стартовыми ценами на GTX 1060 3GB ($199) и GTX 1060 6GB ($249). Собственно, новинка заменяет в линейке компании именно модель с меньшим количеством видеопамяти и урезанным по исполнительным блокам GPU. Кстати, это тоже выглядит как хоть и небольшое, но все же повышение цен на GPU из определенного рыночного сегмента.
В GeForce GTX 1660 используется все та же 192-битная шина памяти, что и у старшего варианта, но дорогую GDDR6-память сменил старый проверенный вариант в виде микросхем GDDR5. Что касается еще одной важной характеристики для графических процессоров — потребления энергии, — то для младшей модели на TU116 компания Nvidia не стала менять теплопакет, оставив то же значение в 120 Вт, что и у GTX 1660 Ti.
Архитектурные особенности
Главное, что отличает TU116 от чипов TU10x с архитектурной точки зрения — отсутствие самой интересной части функциональности, появившейся именно в чипах семейства Turing. Из нового среднебюджетного GPU были убраны аппаратные блоки для ускорения трассировки лучей и тензорные ядра — все для того, чтобы недорогой графический процессор был не слишком сложным и лучше делал свое основное дело — традиционный рендеринг привычным методом растеризации.
С площадью кристалла в 284 мм² чип TU116 получился значительно меньше самого слабого из представленных ранее чипов семейства Turing — TU106. Естественно, и количество транзисторов уменьшилось с 10,8 млрд до 6,6 млрд, что очень серьезно снижает себестоимость производства, очень важную для среднебюджетных графических процессоров. Но если сравнивать TU116 с GP106, то новый GPU примерно настолько же больше него по размеру (200 мм² у GP106), так что изменения в мультипроцессорах Turing тоже не обошлись даром.
По доступным публике данным не слишком просто понять, насколько велик вклад именно RT-ядер и тензорных ядер в сложность старших чипов Turing, так как TU116 имеет меньшее количество мультипроцессоров и других блоков по сравнению с TU106 и напрямую их сравнить не получится. Но давайте все же рассмотрим характеристики нескольких моделей видеокарт Nvidia из двух последних поколений, близких друг к другу по цене:
| GTX 1660 Ti | RTX 2060 | GTX 1060 | |
|---|---|---|---|
| Кодовое имя GPU | TU116 | TU106 | GP106 |
| Кол-во транзисторов, млрд | 6,6 | 10,8 | 4,4 |
| Площадь кристалла, мм² | 284 | 445 | 200 |
| Базовая частота, МГц | 1500 | 1365 | 1506 |
| Турбо-частота, МГц | 1770 | 1680 | 1708 |
| CUDA-ядра, шт | 1536 | 1920 | 1280 |
| Производительность FP32, TFLOPS | 5,5 | 6,5 | 4,4 |
| Тензорные ядра, шт. | 0 | 240 | 0 |
| RT-ядра, шт. | 0 | 30 | 0 |
| Блоки ROP, шт. | 48 | 48 | 48 |
| Блоки TMU, шт. | 96 | 120 | 80 |
| Объем видеопамяти, ГБ | 6 | 6 | 6 |
| Шина памяти, бит | 192 | 192 | 192 |
| Тип памяти | GDDR6 | GDDR6 | GDDR5 |
| Частота памяти, ГГц | 12 | 14 | 8 |
| ПСП памяти, ГБ/с | 288 | 336 | 192 |
| Энергопотребление TDP, Вт | 120 | 160 | 120 |
| Рекомендованная цена, $ | 279 | 349 | 249(299) |
TU116 имеет ту же архитектуру мультипроцессоров, что и видеокарты семейства GeForce RTX, за исключением RT-ядер и тензорных ядер (некоторые подробности будут ниже), так что сравнивать с RTX 2060 новинку можно. В модели GTX 1660 Ti применяется полный чип TU116, и количество мультипроцессоров в нем было сокращено до 24 по сравнению с TU106. Кроме этого, немного снизили частоту GDDR6-памяти с 14 ГГц до 12 ГГц, оставив 192-битную шину. В остальном же эти чипы вполне сравнимы — и в теории, и на практике. Как бы компенсируя меньшее количество исполнительных блоков, GTX 1660 Ti получила чуть большую тактовую частоту, хотя эта разница особой роли не играет.
Если сравнивать по пиковым показателям, то GTX 1660 Ti получился даже чуть быстрее RTX 2060 по филлрейту — из-за одинакового количества блоков ROP и чуть повышенной частоты, а вот по более важным показателям математической и текстурной производительности новинка обеспечивает где-то около 85% производительности старшей RTX 2060. Впрочем, по сравнению с GTX 1060 6GB новая видеокарта минимум на четверть быстрее ее по этим же показателям, по ПСП вообще наполовину, а вот преимущество по филлрейту почти отсутствует. То есть, GTX 1660 Ti должна быть по скорости где-то между этими двумя моделями и близко к уровню еще одной — GTX 1070.
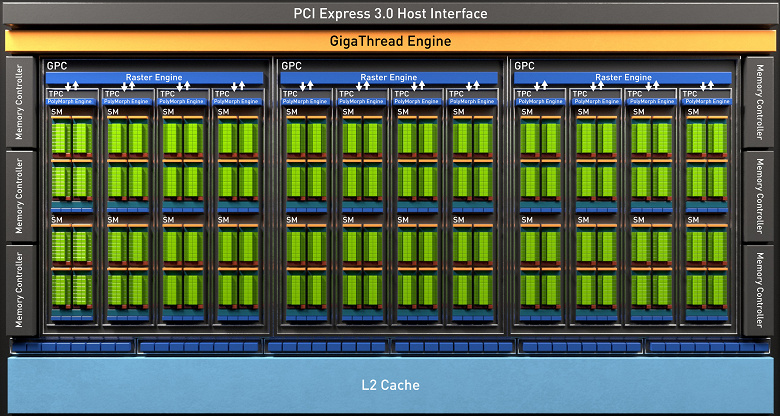
Полная версия чипа TU116 в модификации для GTX 1660 Ti содержит три кластера Graphics Processing Cluster (GPC), и в каждом из них — по четыре кластера Texture Processing Cluster (TPC), состоящих из движков PolyMorph Engine и пары мультипроцессоров SM. В свою очередь, каждый SM состоит из: 64 CUDA-ядер и четырех блоков текстурирования TMU. То есть, всего TU116 содержит 1536 CUDA-ядер в 24 мультипроцессорах. Подсистема памяти состоит из шести 32-битных контроллеров памяти, что дает нам в целом 192-битную шину.
Что касается тактовых частот графического процессора, то базовая частота чипа GeForce GTX 1660 Ti равна 1500 МГц, а турбо-частота достигает 1770 МГц. Как обычно для решений Nvidia, это не максимальная частота, а средняя для нескольких игр и приложений. Реальная частота в каждом случае будет отличаться, так как она зависит как от игры, так и от условий конкретной системы (питания, температура и т. п.). Видеопамять стандарта GDDR6 работает на частоте 12 ГГц, что дает нам очень высокую для среднебюджетного сегмента пропускную способность в 288 ГБ/с.
Кроме отрезания функциональности RTX, TU116 ничем не хуже своих старших братьев — в остальном по своим возможностям он полностью соответствует чипам TU10x, архитектура мультипроцессоров в целом одинакова. И с программной точки зрения, GTX 1660 Ti ничем не отличается от решений GeForce RTX, кроме поддержки аппаратной трассировки лучей и ускорения задач глубокого обучения при помощи тензорных ядер — эти задачи тоже будут выполняться, просто со значительно меньшей скоростью.
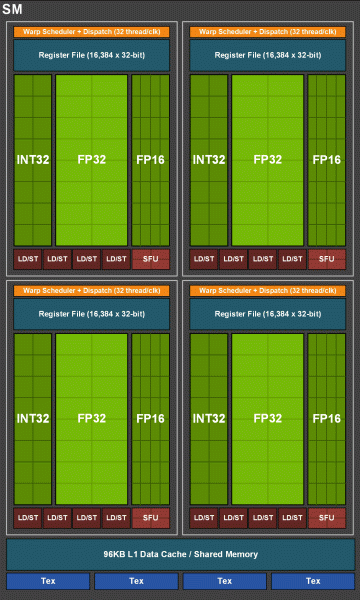
Мультипроцессор в TU116 почти идентичен блокам SM, которые мы видели в старших чипах Turing. Он состоит из четырех разделов и имеет свои текстурные блоки и кэш-память первого уровня. Даже размеры кэшей и регистрового файла в мультипроцессорах не изменились. А вот что изменилось в TU116 по сравнению со старшими чипами семейства, так это объем кэш-памяти второго уровня вне мультипроцессоров. Если старшие чипы Turing имеют по 512 КБ L2-кэша на раздел ROP (и у TU106 всего получается 4 МБ), то TU116 ограничен лишь 256 КБ L2-кэша (1,5 МБ на чип).
Структура нового дизайна мультипроцессоров SM отличается от того, что было в Pascal. Мультипроцессор Turing разделен на четыре раздела — каждый с собственным блоком планирования и распределения (warp scheduler and dispatch unit), и способен выполнять по 32 потока за такт. В разделах есть несколько типов исполнительных блоков: 16 ядер FP32, 16 ядер INT32 и 32 ядра для исполнения операций с точностью FP16. Самое важное отличие заключается в том, что обработкой целочисленных операций и операций с плавающей запятой теперь занимаются разные блоки, а операции со сниженной точностью FP16 выполняются вдвое быстрее, чем FP32.
И это повышает эффективность загрузки блоков GPU. Приведем пример шейдеров из игры Shadow of the Tomb Raider, в которых на каждые 100 инструкций приходится в среднем 38 инструкций INT32 и 62 FP32. Все предыдущие архитектуры Nvidia, включая Pascal, выполняют их последовательно одна за другой, а Turing умеет параллельно выполнять INT и FP, так как в SM появились дополнительные блоки для исполнения целочисленных операций.
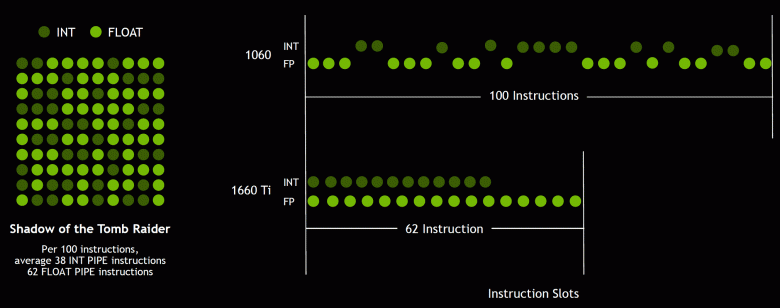
Одновременное исполнение FP- и INT-операций обеспечивает более эффективное исполнение шейдеров, и в сложных случаях прирост получается в полтора раза и более. В частности, общая производительность рендеринга GeForce GTX 1660 Ti в игре Shadow of the Tomb Raider примерно в полтора раза выше, чем у GTX 1060 6GB, хотя это связано не только с указанной модификацией, конечно же.
Также в Turing была значительно улучшена система кэширования — внедрена унифицированная архитектура для разделяемой памяти и кэшей: первого уровня и текстурного. Новая система кэширования имеет вдвое больше блоков загрузки-выгрузки данных (Load-Store Unit — LSU), шире линии передачи данных в кэш-память и обратно (32-бита против 16-бит) и большее их количество, а также втрое больший объем L1-кэша по сравнению с аналогичным GPU из семейства Pascal (GeForce GTX 1060).
Новый дизайн системы кэширования значительно увеличил эффективность кэширования данных и позволяет переконфигурировать размер кэша тогда, когда программистом не используется полный объем разделяемой памяти. L1-кэш может быть объемом 64 КБ, в дополнение к 32 КБ разделяемой памяти на каждый мультипроцессор, или наоборот, можно снизить объем L1-кэша до 32 КБ, оставив 64 КБ на разделяемую память.
Одной из игр, получающих преимущество от улучшений кэширования в Turing, стала Call of Duty Black Ops 4. По результатам внутренних тестов Nvidia, GeForce GTX 1660 Ti примерно на 50% быстрее своей предшественницы GTX 1060 6GB в этой игре — во многом из-за более эффективной работы кэш-памяти. Также наверняка сработала и быстрая GDDR6-память, поддержка которой появилась именно в Turing. GeForce GTX 1660 Ti имеет те же 6 ГБ памяти, подключенной к GPU по 192-битному интерфейсу, как и старшая модель GTX 1060, но из-за установки на нее скоростной GDDR6-памяти, работающей на эффективной частоте в 12 ГГц, новая модель имеет на 50% большую пропускную способность памяти.
Также архитектурой Turing поддерживаются новые технологии для увеличения производительности в играх: Variable Rate Shading (VRS) — переменная частота затенения, Texture-Space Shading — затенение в текстурном пространстве, Multi-View Rendering — отрисовка с нескольких позиций, Mesh Shading — полностью программируемый конвейер обработки геометрии, CR и ROVs — технологии DirectX 12 уровня возможностей Feature Level 12_1.
Переменная частота затенения позволяет реализовать два важных алгоритма адаптивной частоты затенения в зависимости от содержания и движения в сцене — Content Adaptive Shading и Motion Adaptive Shading. Оба алгоритма позволяют изменять частоту затенения для некоторых участков изображения, которые не требуют рендеринга с полным качеством, когда вполне достаточно и меньшего количества выборок для увеличения производительности.
К примеру, Motion Adaptive Shading позволяет регулировать частоту затенения в зависимости от наличия/скорости изменений в сцене. Самый простой и понятный пример — гоночная игра, где центральная часть с автомобилем игрока отрисовывается в полном качестве, а дорога и окружение на периферии кадра рендерятся с худшим качеством, так как они все равно слишком быстро движутся и человеческие глаза и мозг просто не могут увидеть разницу в качестве.
Или взять Content Adaptive Shading, при работе которого частота затенения определяется разницей в цвете соседних пикселей на протяжении нескольких кадров. Если цвета от кадра в кадр меняются слабо, как на поверхности неба, то вполне можно этот участок отрисовать с меньшей частотой затенения, и человек снова не увидит визуальной разницы. Переменная частота затенения уже используется в игре Wolfenstein II: The New Colossus, и меньшая работа по закраске пикселей приносит приличный прирост производительности, помогая GeForce GTX 1660 Ti быть в полтора раза быстрее, чем GTX 1060 6GB.
Часть улучшений в Turing пришла из Volta, а часть — новые архитектурные новинки, которые есть только в новейшем поколении. Некоторым могло показаться, что TU116 правильнее причислять к архитектуре Volta, так как у него нет RT-ядер и тензорных ядер, а многие улучшения в мультипроцессорах уже были сделаны в GV100. Это не соответствует действительности, так как в Turing есть изменения, которые отсутствуют в Volta: поддержка некоторых возможностей DirectX 12 (resource heap tier 2) и технологии, о которых мы выше рассказывали: Mesh Shading, Variable Rate Shading, Texture Space Shading и другие.
Также в архитектуре Turing были улучшены последние слабые места архитектуры Pascal относительно конкурирующей GCN у AMD, которые могли приводить к снижению производительности в ПК-играх на Pascal, так как код был оптимизирован для GCN. У Turing никаких слабостей уже не осталось, она всегда достаточно эффективна, в том числе с применением асинхронного исполнения шейдерных программ, популярного в современных играх.
Отметим еще один важный момент по поводу тензорных ядер. В TU116 их нет, как говорит Nvidia, но удвоенный темп выполнения операций с точностью FP16 остался, но в семействе GeForce RTX они выполняются на том же «железе», что и тензорные операции (при работе используется часть тензорных ядер). Для поддержки этой функциональности в TU116 пришлось оставить урезанную часть тензорных ядер — выделенные FP16-блоки, которые также могут работать одновременно с FP32-блоками (вместо INT, но не все три типа блоков вместе). И с программной точки зрения для приложений не будет никакой разницы, все GPU нового семейства способны выполнять FP16 с удвоенной производительностью.
Впрочем, конкретно в играх эта возможность до сих пор остается не особенно востребованной, так как из популярных проектов используется разве что в Wolfenstein II и Far Cry 5 (для симуляции водной поверхности), да и то — еще неизвестно, остались ли они в последних патчах. То же самое касается и того, что на всех решениях Turing могут выполняться параллельно FP32 FMA и INT32 операции, или FP16 (с удвоенной производительностью) и INT32 операции, или FP32 и ускоренные FP16. Теоретически, на этих FP16 блоках могут параллельно выполняться и тензорные операции, но лишь в теории, поддержки того же DLSS в TU116 нет и вряд ли она будет — тут даже удвоенной скорости FP16 не хватит.
Что касается производительности Turing по сравнению с Pascal, то все улучшения эффективности мультипроцессоров в новой архитектуре значительно улучшили как производительность (в полтора раза по оценке Nvidia), так и энергоэффективность (на 40%). Прирост производительности Turing по количеству исполняемых операций за такт в реальных играх составляет около полутора раз, а при том же уровне энергопотребления среднее преимущество GTX 1660 Ti над GTX 1060 6GB по итоговой частоте кадров можно оценить примерно в 35%-40%.
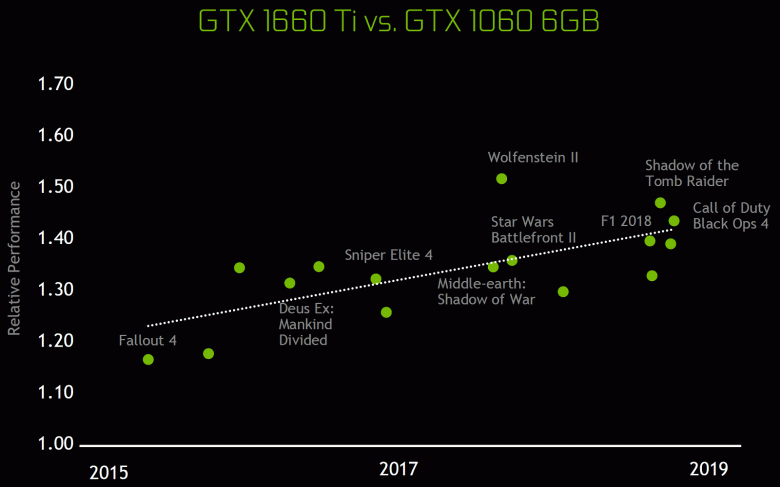
И чем новее игры используются, тем больше преимущество от увеличенной эффективности Turing. Так, если в устаревших проектах вроде Fallout 4 и Deus Ex: Mankind Divided преимущество новинки над GTX 1060 оказывается лишь 20%-30%, то в Shadow of the Tomb Raider и Call of Duty Black Ops 4 оно доходит до 40%-45% и даже более. В целом же можно сказать, что видеокарта модели GeForce GTX 1660 Ti явно разработана для игры в Full HD-разрешении, и она обеспечивает в этих условиях отличную производительность при максимальном качестве картинки.
Похоже, что с выходом решений линейки GeForce GTX 16 (за GTX 1660 Ti вскоре последуют и другие модели), компании Nvidia будет несколько проще продвигать возможности старшего подсемейства GeForce RTX, ведь они будут жестко разделены по возможностям и в более дешевых вариантах поддержки самых современных технологий в ближайшем будущем не ожидается.
Графический ускоритель GeForce GTX 1650
За месяцы, прошедшие с момента анонса линейки видеокарт GeForce, основанной на графических процессорах семейства Turing, было выпущено много моделей GPU. Nvidia традиционно шла от топовой модели вниз, выпуская все менее дорогие варианты, входящие в состав линеек GeForce RTX и GeForce GTX. В апреле 2019 года пришло время и для самой дешевой видеокарты на основе текущей архитектуры Turing, которая получила наименование GeForce GTX 1650.
Новое решение заняло ценовую нишу $149 (на североамериканском рынке) и стало бюджетным вариантом Turing без поддержки аппаратной трассировки лучей и ускорения глубокого обучения. Оно предназначено для игры в разрешении Full HD при не самых высоких настройках графики. Применяемые в этой линейке GPU менее сложны за счет отказа от выделенных специализированных блоков (RT и тензорных ядер) и поэтому дешевле в производстве, что отлично подходит для бюджетной серии. Сначала Nvidia выпустила пару карт GTX 1660: обычную и с приставкой Ti, обе основаны на разных версиях чипа TU116. Теперь младшая серия была расширена при помощи модели GeForce GTX 1650, получившей еще менее сложный графический процессор.
Рассматриваемая сегодня новинка основана на графическом процессоре TU117, также не имеющем RT-ядер и тензорных ядер. Зато этот GPU имеет максимально возможную энергоэффективность в рамках определенного транзисторного бюджета, что важно для современных игр без применения трассировки лучей. Благодаря архитектурным улучшениям, по производительности и энергоэффективности видеокарты семейства Turing превосходят аналогичные GPU из предыдущих семейств компании Nvidia.
Модель GeForce GTX 1650 выглядит довольно интересным решением для обновления видеоподсистемы тех игроков, кто еще не сделал апгрейд на решения линейки GeForce GTX 10 и до сих пор использует видеокарты уровня GeForce GTX 950 или ниже. Новинка предлагает таким пользователям уровень производительности примерно вдвое выше, что особенно важно для требовательных современных игр, но и в самых популярных многопользовательских проектах новый GPU способен дать приличный прирост скорости рендеринга.
| Графический ускоритель GeForce GTX 1650 | |
|---|---|
| Кодовое имя чипа | TU117 |
| Технология производства | 12 нм FinFET |
| Количество транзисторов | 4,7 млрд |
| Площадь ядра | 200 мм² |
| Архитектура | унифицированная, с массивом процессоров для потоковой обработки любых видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | DirectX 12, с поддержкой уровня возможностей Feature Level 12_1 |
| Шина памяти | 128-битная: 4 независимых 32-битных контроллера памяти с поддержкой памяти типов GDDR5 и GDDR6 |
| Частота графического процессора | 1485 (1665) МГц |
| Вычислительные блоки | 14 (из 16 в чипе) потоковых мультипроцессоров, включающих 896 (из 1024) CUDA-ядер для целочисленных расчетов INT32 и вычислений с плавающей запятой FP16/FP32 |
| Блоки текстурирования | 56 (из 64) блоков текстурной адресации и фильтрации с поддержкой FP16/FP32-компонент и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) | 4 широких блока ROP (32 пикселя) с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра |
| Поддержка мониторов | поддержка подключения по интерфейсам HDMI 2.0b и DisplayPort 1.4a |
| Спецификации референсной видеокарты GeForce GTX 1650 | |
|---|---|
| Частота ядра | 1485 (1665) МГц |
| Количество универсальных процессоров | 896 |
| Количество текстурных блоков | 56 |
| Количество блоков блендинга | 32 |
| Эффективная частота памяти | 8 ГГц |
| Тип памяти | GDDR5 |
| Шина памяти | 128 бит |
| Объем памяти | 4 ГБ |
| Пропускная способность памяти | 128 ГБ/с |
| Вычислительная производительность (FP16/FP32) | 6,0/3,0 терафлопс |
| Теоретическая максимальная скорость закраски | 53 гигапикселя/с |
| Теоретическая скорость выборки текстур | 94 гигатекселя/с |
| Шина | PCI Express 3.0 |
| Разъемы | зависит от видеокарты |
| Энергопотребление | до 75 Вт |
| Дополнительное питание | нет (зависит от видеокарты) |
| Число слотов, занимаемых в системном корпусе | 2 |
| Рекомендуемая цена | $149 (11 990 рублей) |
Наименование видеокарты отличается от старшей модели GTX 1660 численным значением, что выглядит логично и соответствует принятой системе наименования видеокарт Nvidia. Как и другие бюджетные модели, видеокарта GTX 1650 не имеет референсного варианта, и производители видеокарт сделали собственные платы на основе внутреннего эталонного дизайна. В продажу сразу же поступило множество вариантов с различными характеристиками и системами охлаждения.
GeForce GTX 1650 заменила в линейке модель предыдущего поколения GTX 1050, которая также была урезана аналогичным образом, но цены на Turing повысились по сравнению с Pascal и в этом случае, как и во всей новой линейке. Если модель GTX 1050 имела рекомендованную цену в $109, то GTX 1650 продается по цене от $149, так что он ближе к GTX 1050 Ti, который имел рекомендованную цену в $139. Впрочем, в этом поколении все цены выросли — каждая из видеокарт семейства Turing продается дороже аналогичной по позиционированию карты на чипе Pascal.
Что касается конкурента, то у AMD есть многочисленные варианты из линейки Radeon RX 500, и они имеют очень хорошее сочетание цены и производительности. Вероятно, правильнее всего будет сравнивать новинку с двумя вариантами Radeon RX 570: с 8 ГБ и 4 ГБ памяти. Младшая модель Radeon RX 570 будет выглядеть привлекательнее за счет меньшей цены, а старшая — за счет большего объема видеопамяти. Впрочем, у Turing (пусть и в урезанном виде) также есть свои преимущества.
В GeForce GTX 1650 используется проверенное сочетание 128-битной шины памяти и GDDR5-памяти. Возможные варианты объема видеопамяти понятны: 2 ГБ, 4 ГБ или 8 ГБ, и минимальный объем видеопамяти для GTX 1650 повысили до 4 ГБ, моделей с 2 ГБ быть не должно, в отличие от имеющихся подобных вариантов GTX 1050. Меньшего объема VRAM уже откровенно мало, а больший вряд ли будет полезен для этой ценовой категории, поэтому и была выбрана золотая середина — 4 ГБ.
Неудивительно, что младшая модель Turing также потребляет энергии меньше остальных видеокарт семейства. Все предыдущие решения этого позиционирования у Nvidia имели энергопотребление до 75 Вт, и GTX 1650 не выбилась из этого ограничения. Так что при референсных частотах этот GPU не требует дополнительного питания и ему хватит 75 Вт, получаемых по шине. Впрочем, партнеры компании иногда решают вопрос альтернативным методом, установив разъем питания для большего разгона и лучшей стабильности.
Количество и тип разъемов вывода информации на дисплеи зависит исключительно от конкретной карты — кто-то из производителей ставит больше разъемов, кто-то меньше, и кто-то решит выделиться необычным набором из серой массы стандартных решений. Сам же по себе новый GPU поддерживает все те же разъемы и стандарты DVI, HDMI, DisplayPort и VirtualLink, что и более мощные решения семейства.
Архитектурные особенности
Как мы уже отмечали выше в тексте о GeForce GTX 1660 Ti, главное отличие TU11x от TU10x — отсутствие аппаратных блоков для ускорения трассировки лучей и тензорных ядер. Это сделано для того, чтобы недорогие графические процессоры были менее сложными и эффективнее справлялись с традиционным рендерингом. В результате, графический процессор TU117 получился значительно проще по количеству транзисторов и площади по сравнению с самым слабым из «полноценных» чипов семейства Turing.
По сути, это упрощенная версия TU116 с меньшим количеством исполнительных блоков, но теми же поддерживаемыми технологиями. Из TU116 как будто были удалены: треть CUDA-ядер, треть каналов памяти и блоков ROP, и все это для того, чтобы получить сравнительно простой GPU для бюджетного решения. Впрочем, эта простота относительна — с его то 200 мм² площадью и 4,7 млрд транзисторов, получился практически такой же по размеру чип, как GP106, известный нам по GeForce GTX 1060 — и он явно более высокого класса.
Для наглядности разницы между различными моделями графических процессоров предлагаем рассмотреть характеристики нескольких видеокарт Nvidia из последних поколений, близких друг к другу по цене:
| GTX 1650 | GTX 1660 | GTX 1050 Ti | GTX 1050 | |
|---|---|---|---|---|
| Кодовое имя GPU | TU117 | TU116 | GP107 | GP107 |
| Кол-во транзисторов, млрд | 4,7 | 6,6 | 3,3 | 3,3 |
| Площадь кристалла, мм² | 200 | 284 | 132 | 132 |
| Базовая частота, МГц | 1485 | 1530 | 1290 | 1354 |
| Турбо-частота, МГц | 1665 | 1785 | 1392 | 1455 |
| CUDA-ядра, шт | 896 | 1408 | 768 | 640 |
| Производительность FP32, TFLOPS | 3,0 | 5,0 | 2,1 | 1,9 |
| Блоки ROP, шт | 32 | 48 | 32 | 32 |
| Блоки TMU, шт | 56 | 88 | 120 | 80 |
| Объем видеопамяти, ГБ | 4 | 6 | 4 | 2 |
| Шина памяти, бит | 128 | 192 | 128 | 128 |
| Тип памяти | GDDR5 | GDDR5 | GDDR5 | GDDR5 |
| Частота памяти, ГГц | 8 | 8 | 7 | 7 |
| ПСП памяти, ГБ/с | 128 | 192 | 112 | 112 |
| Энергопотребление TDP, Вт | 75 | 120 | 75 | 75 |
| Рекомендованная цена, $ | 149 | 219 | 139 | 109 |
Модификация TU117 в составе GeForce GTX 1650 имеет два кластера GPC, содержащие 896 CUDA-ядер, что совсем немногим больше, чем у GeForce GTX 1050, но из-за архитектурных улучшений в Turing, производительность новинки должна быть выше даже при прочих равных. Новый чип имеет в своем составе 32 блока ROP и 128-битную шину памяти, обеспечивающую работу GDDR5-памяти на эффективной частоте в 8 ГГц. Итоговая пропускная способность памяти получается 128 ГБ/с, что лишь немногим выше аналогичного показателя для GTX 1050.
Интересно, что CUDA-ядра работают на несколько меньшей тактовой частоте, по сравнению с другими решениями семейства Turing — графический процессор GTX 1650 работает на турбо-частоте в 1665 МГц. Чисто теоретически, GTX 1650 должен обеспечить примерно две трети производительности от старшей модели в линейке Nvidia — GeForce GTX 1660, но на практике может быть даже чуть ближе к ней.
Вполне возможно, что в дальнейшем на основе TU117 будут выпущены и еще какие-то решения, но пока что речь идет исключительно о GeForce GTX 1650, модели с приставкой Ti не было выпущено. Что тем более интересно, так как в GTX 1650 применяется не полная версия чипа TU117. У этой версии выключен один кластер TPC, состоящий из пары мультипроцессоров SM по 64 CUDA-ядер. Так что у Nvidia есть еще небольшой задел для маневра — к примеру, ускоренного по тактовой частоте полноценного TU117 с большим количеством ядер в виде GTX 1650 Ti.
Если сравнивать по пиковым показателям, то GTX 1650 должна обеспечить около 60%-70% производительности GTX 1660, а по сравнению с GTX 1050 новая видеокарта быстрее решения архитектуры Pascal вообще по всем показателям, и даже GTX 1050 Ti уступает новинке. Но главное преимущество Turing заключается в архитектурных улучшениях и максимальной эффективности. В обзоре GeForce GTX 1660 Ti мы подробно писали об изменениях в TU116 и основных его возможностях, это же относится и к TU117. Эти чипы по своей функциональности соответствует старшим графическим процессорам семейства TU10x, за исключением поддержки аппаратной трассировки лучей и ускорения задач глубокого обучения при помощи тензорных ядер.
В целом, младший графический процессор TU117 обеспечивает неплохой баланс производительности и энергопотребления, поддерживая почти все возможности старших чипов семейства Turing, нацеленные на повышение производительности и энергоэффективности, включая поддержку одновременного выполнения целочисленных операций и операций с плавающей точкой, унифицированную архитектуру памяти с увеличенным объемом L1-кэша.
По данным Nvidia, в Full HD-разрешении модель GeForce GTX 1650 оказалась примерно вдвое быстрее, чем GTX 950, и до 70% быстрее аналогичной модели прошлого поколения — GTX 1050. А так как новинка не требует подключения дополнительного питания, то она стала доступным и простым вариантом для модернизации графической подсистемы для владельцев подобных GPU. Кроме этого, GeForce GTX 1650 будет неплохим выбором и для новых игровых ПК начального уровня.
Такая видеокарта, не требующая дополнительного питания, отлично подойдет и для тех систем, которые ограничены по потреблению энергии, вроде домашних кинотеатров. Хотя дискретные GPU не очень часто используются в таких системах, но более мощный графический процессор с современными возможностями станет отличной заменой для решений серии GTX 1050. Единственный нюанс — хотя можно было бы предположить, что TU117 по своим видеовозможностям не будет отличаться от TU116, это не так.
Если в GTX 1660 применяется новый блок NVEnc последнего поколения (Turing), то GTX 1650 отличается блоком предыдущей версии (Volta). Применяемая в новом GPU версия примерно аналогична той, что была в Pascal и обеспечивает то же качество закодированного видео, что и GTX 1050, например. А блок NVEnc семейства Turing работает на 15% эффективнее и имеет дополнительные улучшения для снижения количества артефактов. Впрочем, возможностей NVEnc поколения Volta достаточно для бюджетных ПК, и в целом GTX 1650 является отличной картой и для HTPC, не требующей подключения дополнительного питания.
Играем на карте для майнинга Nvidia в 2022 году
В данной статье я расскажу вам о способах, которые позволяют играть в игры и использовать карту для майнинга от Nvidia как обычный графический ускоритель.
Введение.
реклама
В середине 2019 года в интернете было опубликовано огромное количество однотипного материала с инструкциями как играть в игры на картах для майнинга от Nvidia. К счастью, или к сожалению, для русскоговорящего пользователя на текущий момент в 99% случаев инструкцией будет являться ряд видеороликов на площадке YouTube от Maddy MURK, созданных еще в 2019 году.
Качество и информативность этих видеороликов значительно хромает, а актуальность сильно устарела, появились более доступные способы, которыми я хочу с ваши поделиться.
Так что, если вы заинтересованы в том, что бы в конце 2022 года купить видеокарту для игр совсем уж за дешево, то данная статья для вас.
Данная статья является инструкцией к действию только под Windows.
реклама
Среди разновидностей карт, выпущенных для майнинга, приведу несколько:
P106-090 — аналог GTX 1050 Ti
P106-100— аналог GTX 1060 6GB
P104-100 —аналог GTX 1070 (4,8 гб.)
P104-101 — аналог GTX 1080 (с меньшим объемом памяти)
P102-100 — GTX 1080 Ti (с меньшим объемом памяти)
P102-101
В том числе, возможно использовать такие карты как NVIDIA CMP и так далее.
реклама
На торговой площадке цены на P106-100 в среднем составляют 2500р, можно найти как за 1500р., так и за 4000р.+ А ведь это аналог GTX 1060 6GB , цены на которые значительно выше.

Понятное дело, что угадать на сколько карта будет жива и как ее обслуживали не возможно, тем не менее, решает цена.
реклама
Лично мой путь начался с покупки P106-100 за 2000р. с корпусными вентиляторами.
За картой не следили, система питания была вся в пыли, чипы памяти немного поджарены, оставалась надежда, что родные вентиляторы умерли быстрее, чем карта была умайнена в хлам и корпусные вентиляторы, работающие на максимальной скорости вращения, хоть как — то ее спасли.
В любом случае, она работает стабильно и исправно.



Теперь к сути, что и как:
Вам необходимо наличие iGPU , либо второй видеокарты. Windows 10 1803 или новее.
1. Драйвера 417.35 и выше
Начиная с драйвера 417.35 и выше были внедрены изменения, не позволяющие ранее доступными способами вносить изменения и заставлять карты для майнинга поддерживать DirectCompute и соответственно играть в игры.
На текущий момент энтузиастами выпущена программа, позволяющая в автоматическом режиме вносить необходимые изменения в драйвер и, что не мало важно, подписывать его.
Инструкция довольно проста:

- Распаковываем скаченный драйвер..
- Перемещаем файлы из скаченного архива в папку с драйвером.
- Запускаем Patch.bat с правами администратора.
- Проверяем, чтобы /Display.Driver/nv_disp.cat был подписан сторонним сертификатом.
- Устанавливаем драйвер в ручном режиме, выбрав модель 3D видеокарты, а не карты для майнинга.
В результате драйвер будет установлен и появится поддержка DirectCompute.

Поделюсь ссылками на уже измененные драйверы.
2. Драйвера 417.23 и ниже
1. Устанавливаем драйвер вручную, выбрав аналог вашей видеокарты.(см. перечень выше)
2. Переходим в редактор реестра по адресу HKEY_LOCAL_MACHINESYSTEMControlSet001ControlClass\0001 (последняя папка может меняться в зависимости от многих факторов)
3. Вносим изменения в ключи
AdapterType — 0, либо 4 в случае, если у вас не будет результата.
EnableMsHybrid -1 (Intel) , либо 2 (AMD). Хотя, на самом деле, не советую привязываться к конфигурации и попробовать оба значения, если у вас не будет результата.

4. Сохранить изменения и выполнить перезагрузку.
5. В результате появится поддержка DirectCompute.
3. Как играть?
При наличии iGPU
1. Необходимо войти в настройки Панели управления Nvidia
2. В разделе Manage 3D Setting необходимо выбрать вашу карту как «Высокопроизводительный процессор Nvidia»

3. Зайти в настройки Windows- Система — Дисплей — Настройки графики — выбрать интересующее приложение и в свойствах для него указать высокая производительность, где будет указана Ваша видеокарта

Без iGPU, использую вторую видеокарту для вывода картинки на монитор — просто зайти в «Управление компьютером» и отключить видеокарту, используемую для вывода изображения. В данном случае потеря производительности будет несколько выше.
Вы прекрасны!
За символические деньги, тем более намного дешевле RX470-580 вы можете получить в свое распоряжение игровую видеокарту, которая не предназначена для этого.
Падение производительности есть, но оно в пределах 5-15% от аналога.
За видео сравнениями, производительностью вам на YouTube.
Подпишитесь на наш канал в Яндекс.Дзен или telegram-канал @overclockers_news — это удобные способы следить за новыми материалами на сайте. С картинками, расширенными описаниями и без рекламы.
Лучшие видеокарты Nvidia GeForce RTX в 2023 году
Чтобы собрать хороший игровой ПК, вам необходимо добавить к нему хорошую видеокарту. Даже самым лучшим центральным процессорам требуется отдельная видеокарты, чтобы вы могли делать то, что у вас получается лучше всего — будь то игры, создание контента или любые задачи по 3D-редактированию.
Конечно, есть процессоры со встроенными видеокартами, но они не дадут вам наилучшей графической производительности, особенно для игр.
В этой статье мы рассмотрим лучшие видеокарты Nvidia, доступные на рынке для разных бюджетов и задач. Nvidia лидирует в области графических процессоров.
Компания установила высокую планку в своем поколении Ampere и поднимает ее еще выше с новой серией Ada Lovelace 40. У AMD также есть много хороших графических процессоров на рынке, но вы не можете не обращать внимание на видеокарты Nvidia.
Наш выбор лучшей видеокарты Nvidia в целом: Nvidia GeForce RTX 3080
GeForce RTX 3080 — не самая быстрая и мощная видеокарта Nvidia. Но в целом, это лучший универсал. Даже с появлением RTX 4080 ситуация не изменилась благодаря доступности 3080.
В основе графического процессора Nvidia RTX 3080 лежит GA102. По сути, это тот же чип, который используется как в RTX 3080, так и в графическом процессоре RTX 3090.
Вариант GA102, который используется в RTX 3080, может похвастаться 8704 ядрами Cuda. Хотя это меньше, чем у графического процессора RTX 3090, но это значительно больше, чем у предыдущего поколения. Ядра CUDA распределены по 68 потоковым мультипроцессорам (SM). RTX 3080 имеет 28,3 млрд транзисторов, и тактовая частота графического процессора может составить 1710 МГц.
Видеокарта Nvidia GeForce RTX 3080 также поставляется с 10 ГБ памяти GDDR6X, работающей через агрегированный 320-битный интерфейс памяти. Графический процессор обеспечивает пропускную способность 760 ГБ/с для сравнения, что значительно выше пропускной способности менее 500 ГБ/с карт GDDR6 Turing, выпущенных ранее.

Карта Nvidia Founders Edition рассчитана на 320 Вт. Nvidia рекомендует блок питания мощностью 750 Вт для этого графического процессора, хотя мы считаем, что выбор мощности 850 Вт или выше был бы более более подходящим для запуска мощной игровой системы.
Nvidia также использует новый специальный радиатор для своих более поздних графических процессоров Ampere. Вы также получаете два вентилятора, а специальная конструкция сквозного потока позволяет графическому процессору «дышать свежим воздухом» для повышения эффективности охлаждения. Рекомендуется поддерживать надлежащий поток воздуха внутри корпуса ПК, чтобы избежать теплового дросселирования с RTX 3080.
Что касается производительности, RTX 3080 легко справляется с играми в разрешении 4K со скоростью 60 кадров в секунду. На данный момент это один из самых мощных графических процессоров на рынке.
Поднять на уровень выше с RTX 3090, вы получите лишь незначительное повышение производительности по более высокойцене. RTX 3080 также отлично подходит для трассировки лучей благодаря 68 ядрам RT и поддержке DLSS 2.0. Это очень хорошая видеокарта, и она останется такой на еще на долгие годы.
Лучшая видеокарта Nvidia для игр 4K: Nvidia GeForce RTX 4080
GeForce RTX 4080 от Nvidia — вторая в списке лучших видеокарт компании в последней серии RTX 40. Хотя она значительно дешевле, чем флагманская RTX 4090, она все равно достаточно дорогая.
RTX 4080 использует кристалл AD103, который используется для нескольких карт Nvidia верхнего среднего и высокого уровня RTX 40. Он имеет 9728 ядер Cuda, что примерно на 6000 меньше, чем у RTX 4090, в котором используется более крупный кристалл AD102.
Эти ядра организованы в 76 потоковых мультипроцессоров, представляющих большую часть из 46 миллиардов транзисторов 4080. Несмотря на все ядра, 4080 способен поддерживать относительно высокую базовую тактовую частоту 2205 МГц и ускорение 2505 МГц.
Nvidia рекомендует блок питания мощностью 700 Вт на ПК с этим графическим процессором, но вам может понадобиться больше, если вы сочетаете его с другими высокопроизводительными компонентами.
4080 также поставляется с 16 ГБ памяти GDDR6X, которая является самым быстрым типом VRAM, за исключением HBM2 (который обычно используется на гораздо более дорогих графических процессорах).

С 256-битной шиной пропускная способность 4080 составляет 716,8 ГБ/с, что на самом деле меньше, чем у RTX 3080 10 ГБ. Однако это не означает худшую производительность; Nvidia всегда очень хорошо повышала эффективность использования пропускной способности памяти.
Благодаря новым архитектурным улучшениям RTX 4080 примерно на 20-30% быстрее, чем RTX 3090, имея при этом примерно такое же количество ядер.
С видеокартой RTX 4080 можно легко играть в игры с разрешением 4K с частотой кадров значительно выше 60 кадров в секунду даже без технологий масштабирования, таких как DLSS.
Производительность трассировки лучей также очень хороша, как и у других высокопроизводительных видеокарт Nvidia. Существенная разница в стоимости не позволяет рассматривать её как замену RTX 3080, но этот графический процессор, несомненно, быстр и оснащен современными функциями.
Самая быстрая и мощная видеокарта: Nvidia GeForce RTX 4090
Nvidia RTX 4090 — самая мощная потребительская видеокарта, которую можно купить на рынке. Она представляет собой лучшее из того, что может предложить Nvidia, и легко превосходит все остальные, когда речь идет о чистой производительности.
Скорее всего, чересчур мощной особенно если вы рассматриваете её исключительно для игр. RTX 4090 настолько мощная, что ни 4K, ни трассировка лучей в текущих играх не могут приблизить ее к пределу своих возможностей. Большую часть времени она будет работать вполсилы.
RTX 4090 больше подходит для создателей контента и тех, кто запускает сложные приложения, которые выиграют от мощного ускорения графического процессора. Это первый графический процессор Nvidia с аппаратным кодировщиком AV1, хотя кодировщик NVENC тоже не промах.
Например, используя RTX 4090 с DaVinci Resolve, нам удалось закодировать видео 4K60 продолжительностью 4:30 с битрейтом 40 000 с использованием NVENC всего за 96 секунд. Огромная мощность также означает, что у вас не будет замедления при очистке временных шкал и применении правок, даже без использования прокси-серверов или временных шкал с более низким разрешением.
Видеокарта RTX 4090 построена на новой архитектуре Ada Lovelace от Nvidia и содержит колоссальный графический процессор AD102 с 16 382 ядрами Cuda, 24 ГБ видеопамяти GDDR6X, базовой тактовой частотой 2,23 ГГц и ядрами трассировки лучей Nvidia 3-го поколения.

Это первый графический процессор Nvidia, который также поддерживает DLSS 3.0 и имеет выходы HDMI 2.1 на задней панели. DisplayPort ограничен 1.4, что на данный момент нормально, и он работает от слота PCIe 4 x16 на вашей материнской плате. Он рассчитан на 450 Вт TGP, поэтому он потребляет много энергии и использует новый разъем питания 12VHPWR.
В долгосрочной перспективе это лучше, потому что будет достаточно одного кабеля от блока питания ATX 3.0 (способного выдать до 600 Вт), но пока Nvidia включает в комплект довольно нужный, но все же неудачный адаптер. Вам понадобится блок питания мощностью 850 Вт, хотя мы рекомендуем не менее 1000 Вт, чтобы иметь запас по мощности.
Этот голиаф также огромен физически. Founders Edition, вероятно, самый маленький из них, но даже в этом случае он использует три слота PCIe и с легкостью заполнит корпус Mid-Tower. Видеокарты сторонних производителей еще больше.
В общем, Nvidia RTX 4090 это нишевая видеокарта для профессионального использования. Она излишне для игр в настоящее время и сейчас, её приобретение имеет смысл для профессиональной работы и создания контента. Все характеристики в RTX 4090 велики, но это несомненно, впечатляет. Сейчас просто нет ничего, что могло бы конкурировать с RTX 4090.
Лучшая видеокарта Nvidia для игр с разрешением 1440p: Nvidia GeForce RTX 3070
Видеокарта RTX 3070 находится в середине линейки 30-й серии, и теперь, когда цены на видеокарты стабилизировались, она снова стала чрезвычайно привлекательной.
RTX 3070 использует GA104 с 17,4 миллиардами транзисторов и 46 SM. Он содержит 5888 ядер GPU, 184 ядра Tensor и 46 ядер RT для трассировки лучей. Да, он также поддерживает трассировку лучей, и при этом достаточно надежен даже в разрешении 1440p.
Конечно, DLSS 2.0 также играет огромную роль, но производительность трассировки лучей у карт Nvidia, как правило, лучше, чем у AMD. RTX 3070 может похвастаться базовой тактовой частотой 1500 МГц и тактовой частотой 1725 МГц.

Этот графический процессор содержит 8 ГБ видеопамяти по 256-битной шине памяти для пропускной способности памяти 512 ГБ/с. RTX 3070 рассчитан на мощность 220 Вт, поэтому мы считаем, что даже блока питания мощностью 750 Вт должно хватить для работы ПК с графическим процессором RTX 3070.
Видеокарта RTX 3070 отлично подходит для игр с разрешением 1440p и высокой частотой кадров. Компромиссов меньше, чем с 3060 или 3060 Ti, поэтому можно просто выставить максимальные настройки и оставить все как есть.
RTX 3070 может запускать игры в разрешении 4K, но это не то, ради чего стоит её покупать. Как и другие графические процессоры Nvidia, RTX 3070 также имеет приложения для профессиональной работы и создания контента. Она обладает большой вычислительной мощностью, а наличие кодировщика NVENC делает её лучшим другом стримера.
К сожалению, как и в случае с остальной частью 30-й серии, на подходе более новые варианты. Прямой замены RTX 3070 пока нет, хотя многие утверждают, что RTX 4070 Ti — это именно то, что нужно.
RTX 3070 по-прежнему стоит покупать, и она будет хороша в течение многих лет, особенно если приобрести её по выгодной цене.
Лучшая видеокарта Nvidia для игр с разрешением 1080p: Nvidia GeForce RTX 3060 Ti
Видеокарта Nvidia GeForce RTX 3060 Ti — это то, что мы бы назвали лучшей видеокартой для большинства пользователей. Почему? Потому что большинство людей по-прежнему предпочитают игры в разрешении 1080p.
RTX 3060 Ti в настоящее время является лучшим графическим процессором Nvidia, который вы можете купить, если это ваша цель игры в разрешении 1080p и вы хотите, чтобы частота кадров была абсолютно высокой.
Nvidia GeForce RTX 3060 Ti основана на архитектуре Ampere. Он оснащен 8 ГБ видеопамяти GDDR6 в сочетании с потоковыми мультипроцессорами (SM) на 38 ампер. Он содержит 4864 ядра CUDA по сравнению с 2176 ядрами в RTX 2060 Super.
Энергопотребление, естественно, тоже увеличилось. RTX 3060 Ti теперь рассчитан на 200 Вт, по сравнению со 175 Вт RTX 2060 Super предыдущего поколения. Это определенно увеличение, но оно не является существенным, чтобы обязательно поменять блок питания.

GeForce RTX 3060 Ti также поставляется с тензорными ядрами для рабочих нагрузок ИИ, таких как DLSS и других. Он также имеет выделенные ядра RT для трассировки лучей. 3060 Ti обеспечивает надежную трассировку лучей в разрешении 1080p, что делает его отличным вариантом для бескомпромиссного игрового процесса.
Производительность игр в разрешении 1440p становится немного натянутой для этого графического процессора, поэтому мы рекомендуем придерживаться настроек 1080p с 3060 Ti.
Графический процессор RTX 3060 Ti Founders Edition идентичен RTX 3070 FE. Они также имеют одинаковые размеры, одинаковое количество открытых плавников и одинаковое количество вентиляторов.
Карты сторонних производителей от OEM-партнеров будут иметь другой дизайн, но общая производительность будет более или менее одинаковой. Во всяком случае, партнерские карты могут быть немного лучше из-за более эффективного теплового решения.
Лучшая бюджетная видеокарта Nvidia начального уровня: Nvidia GeForce GTX 1660 Super
Если вы собираете бюджетный игровой ПК, вы не будете слишком много думать о трассировке лучей, разрешении 4K или максимальных настройках графики. Но это не значит, что вы должны идти на компромисс ради хорошего игрового опыта.
GeForce GTX 1660 Super — это видеокартой без каких-либо возможностей трассировки лучей, которые вы найдете на более дорогих устройствах RTX, но обратите внимание, что мы рекомендуем именно GTX 1660 Super, а не обычную 1660, поскольку эта версия предлагает дополнительную производительность, которую не хочется упускать.
GTX 1660 Super должна сослужить вам хорошую службу благодаря надежной игровой производительности в разрешении 1080p. Это также отличный вариант для тех, кто хочет начать играть в такие киберспортивные игры, как CS:GO, LoL, Valorant и другие.

GTX 1660 Super основана на старой архитектуре Turing. Он поставляется с базовой тактовой частотой 1530 МГц и тактовой частотой до 1785 МГц. Вы получаете только 6 ГБ видеопамяти GDDR5, но этого должно быть достаточно для запуска игр, которые она поддерживает.
Она также использует старый тип видеопамяти GDDR5, что делает его более доступной, чем новые графические процессоры с памятью GDDR6. GTX 1660 Super имеет 192-битный интерфейс памяти, обеспечивающий общую пропускную способность памяти 336 ГБ/с.
Также стоит отметить, что Nvidia не продает вариант Founders Edition для этого графического процессора. Вам придется полагаться на партнерские карты, которые могут быть дороже в зависимости от характеристик и радиатора.
Одна из основных причин, по которой мы рекомендуем покупать GTX 1660 Super, заключается в том, что она доступна по цене, компактна и способна работать там, где это необходимо.
Это значительно лучше, чем встроенная графика, и даже дешевле новых графических процессоров Intel Arc, хотя и не так мощно. GTX 1660 Super идеальная карта для начинающих, или просто пытаетесь свести свой бюджет к минимуму.
Источник https://www.ixbt.com/3dv/nvidia-geforce-20-overview.html
Источник https://overclockers.ru/blog/13nikita/show/81635/igraem-na-karte-dlya-majninga-nvidia-v-2022-godu
Источник https://drongeek.ru/rating/luchshie-videokarty-nvidia-geforce-rtx-v-2023-godu